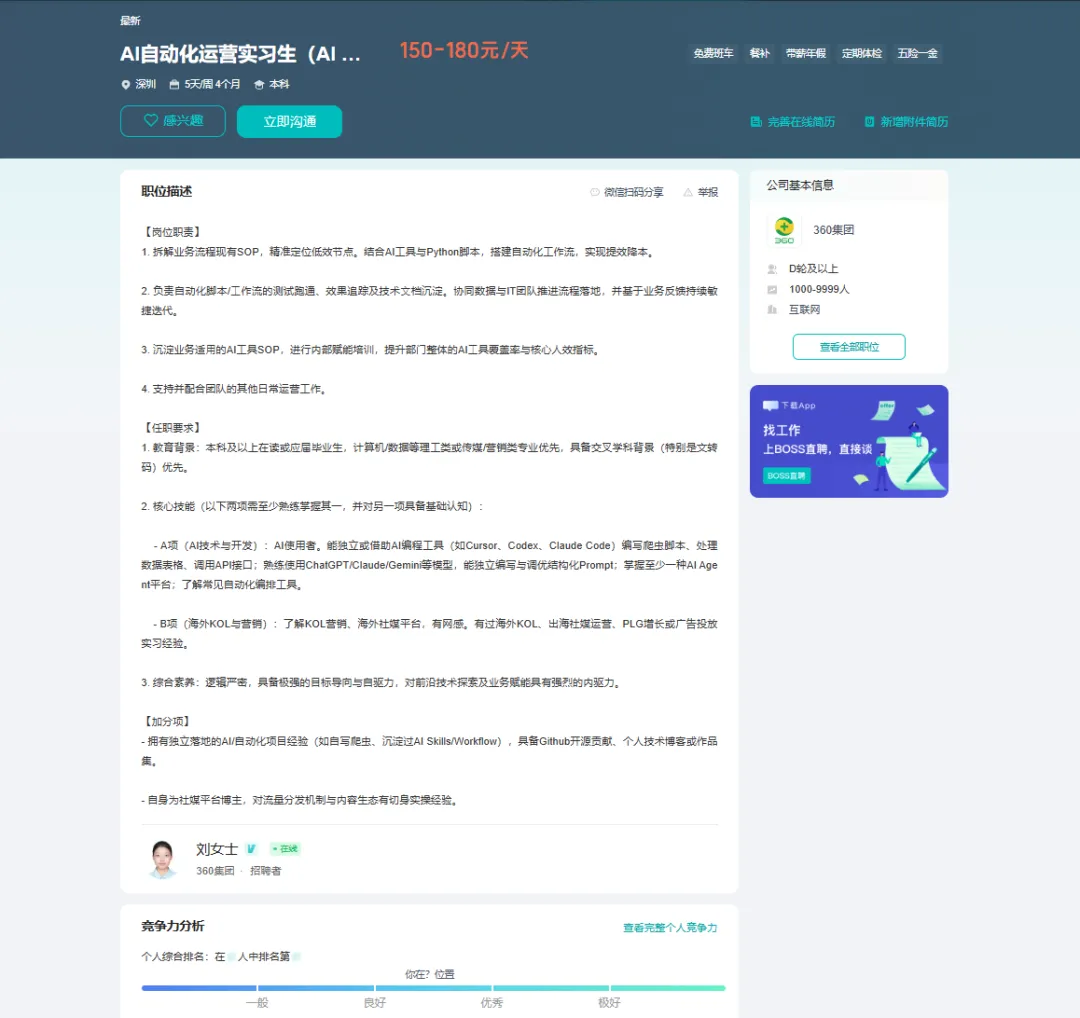
💡应聘技术问题
问题:"用 Cursor、Claude Code 这类 AI 编程工具写出来的脚本,怎么保证它在生产环境不会突然翻车?"
参考答案:
代码能让 AI 写出来跑通,不代表能直接上生产。几个实操点:
写代码时,提示词里就明确运行环境(Python 版本、依赖、输入输出格式),让模型少做"自由发挥"。涉及外部 API 调用的地方,让它把异常分支写全,不要只写 happy path。
审查必须自己来,重点看错误处理、资源释放(文件句柄、数据库连接)、边界条件。AI 写代码常见的几个坑:吞掉异常、循环里重复初始化、hardcode 测试数据。
核心函数补单元测试。幂等操作要重点测(重复执行结果是否一致)。有外部依赖就用 mock 或者沙箱环境跑。
上线先灰度,小流量跑一两天,看错误率和执行时长。关键脚本加监控告警——执行失败、耗时超阈值都告警出来。
跑稳的脚本整理成可复用模板(提示词 + 代码骨架),避免下次重新生成风格不一致的版本。
问题:"写结构化 Prompt 的时候,长上下文容易'失忆'、指令会被后面的内容稀释,怎么处理?"
参考答案:
长上下文失效的本质是注意力分散——指令被正文噪声稀释。几个实操做法:
把"必须遵守的规则"放在开头和结尾各写一次,正文用示例或数据展开。模型对首尾位置的注意力通常比中间高。
用 XML 或 Markdown 标签切分模块,让模型按结构定位:
...............
长文档不要直接全文粘贴。预处理用 RAG 或关键词检索取出相关片段,Prompt 里只放片段 + 来源。上下文窗口留给"当前任务相关"的内容。
输出格式不稳定时,锚定 1-3 个 few-shot 示例,比写一堆规则更管用。
在 Prompt 末尾让模型"先生成结果,再用一段话检查自己是否满足所有约束",相当于一次自检。
问题:"你熟悉的 AI Agent 平台(比如 Coze、Dify、n8n)搭建自动化工作流时,有什么差异?怎么选?"
参考答案:
这三个平台定位不一样。
Coze(扣子) 是字节系,国内访问友好,插件和工具生态偏向 C 端场景(小红书、抖音、飞书)。搭聊天 Bot 和轻量工作流快,但定制化能力受限,复杂业务逻辑需要绕。
Dify 开源,支持私有部署,适合企业内部落地。RAG 和工作流编排比较均衡,LLM 节点、工具节点、知识库节点都是现成的。缺点是 UI 编排复杂工作流会比较绕,不如写代码直观。
n8n 也开源,强调"通用自动化",更像一个 AI 加持版的 Zapier。触发方式多样(Webhook、定时、IM 消息、表单提交),节点库丰富,适合做跨系统数据流转。AI 能力通过 OpenAI/Hugging Face 节点接入,需要自己拼。
选型主要看四点:
- 数据合规
- 触发来源大量 Webhook/IM 选 n8n;C 端用户交互选 Coze 更省事。
- 团队能力业务同学主导选 Coze/Dify(低代码),研发同学主导选 n8n 或直接写代码。
- 成本
问题:"讲一个你独立完成过的自动化项目,重点说清楚背景、你做了什么、踩过什么坑、最终提效多少。"
参考答案:
按 STAR 法则展开:
- 背景和目标原来 X 流程每周要花 Y 小时人工做,瓶颈在 Z;目标是把 X 流程自动化,每周节省 Y 小时,错误率从 A% 降到 B% 以下。
- 方案技术栈用 Python + 某个 AI 工具/Agent 平台;数据从 API / 爬虫 / 内部数据库来;调度用定时任务或事件触发。
- 踩过的坑某个 API 限流,加了重试 + 退避;数据格式不一致,加了清洗和归一化层;AI 生成结果不稳定,加了校验环节。
- 结果每周节省 X 小时,错误率从 A% 降到 B%,后续被推广到 Y 个业务线。
如果还没做过完整项目,可以讲一个"半自动 + AI 辅助"的小项目。比如用 Cursor 写一个周报生成脚本、用 Dify 搭一个 FAQ 机器人。关键是把"自己解决了什么问题、用什么方法、效果如何"讲清楚。
问题:"假设要搭一个自动化工作流,采集指定海外 KOL 在 Instagram 和 TikTok 近 30 天的发布内容、互动数据和粉丝增长曲线,你会怎么设计?"
参考答案:
分四层设计。
数据采集层优先用平台官方 API(Instagram Graph API、TikTok Research API),合规且稳定。没有 API 权限的部分用爬虫兜底,必须控制频率、加账号池和代理,遵守 robots.txt。采集字段包括发布内容(文案、图片/视频 URL、标签)、互动(点赞、评论、分享、收藏)、账号维度(粉丝数、关注数、近期增长)。
调度层用定时任务(每天跑)+ 增量更新(只拉新增内容)。失败任务进重试队列,超过 N 次告警。任务状态写日志,方便排查。
数据层把原始数据进数据仓库(如 PostgreSQL / BigQuery),按 KOL ID + 日期分区。清洗层做去重、字段归一化、互动率计算。衍生指标(互动率、增长斜率、内容类型分布)用 SQL 或 Pandas 算。
输出层做看板可视化:KOL 列表 + 关键指标 + 趋势图。异常告警(粉丝数突增/突降、互动率异常波动)通知运营。数据回流到 AI 工作流,让 LLM 自动生成周报或异常分析。
几个容易踩的坑:Instagram 私有不公开数据要靠商业 API,不要硬爬;TikTok 视频元数据经常变,解析逻辑要写可插拔的;跨时区数据要带时区戳,避免汇总时错位。
🎯应聘面试准备
问:想应聘上述岗位,需要做哪些准备?
答:
简历优化
1. 核心信息前置
- 学历背景写清楚。本科及以上在读或应届毕业生,计算机/数据等理工或传媒/营销类专业优先,具备交叉学科背景(特别是文转码)优先。
- 工作经验突出独立或主导的自动化项目、AI 工具落地经验,标出节省的人力/时间。
- 技术栈明确:Python 脚本、AI 编程工具(Cursor/Codex/Claude Code)、Prompt 工程、AI Agent 平台。
2. 匹配岗位关键词
- 技术栈:Python、API 调度、爬虫、数据处理
- 工程能力:自动化工作流设计、测试调通、效果追踪、技术文档沉淀
- 工具与平台:Cursor、Codex、Claude Code、ChatGPT、Claude、Gemini、Coze/Dify/n8n 等 AI Agent 平台
- 能力标签:流程拆解、SOP 沉淀、跨团队协作、AI 工具内部赋能
技能梳理
- AI 编程工具实操能用 Cursor 或 Claude Code 从零搭一个完整自动化项目(爬虫 + 数据处理 + 定时调度),把过程写到博客或 GitHub。
- Prompt 工程能针对长上下文、复杂任务写出稳定的结构化 Prompt,沉淀 2-3 个常用模板。
- AI Agent 平台至少深入用过 Coze、Dify、n8n 其中一个,能独立搭出可跑的工作流,理解触发、错误处理、扩展点。
- 海外 KOL 与营销(加分)熟悉 1-2 个海外社媒平台的内容生态,了解 KOL 选号逻辑和 PLG 增长常用打法。
- 文档与赋能能写 SOP、做内部分享,把单点经验变成团队可复用的资产。
面试准备
经典问题
- 你用 Cursor/Claude Code 写过的最复杂的一个项目是什么?遇到了什么问题?
- 写 Prompt 的时候,输出格式不稳定怎么处理?
- 你对"AI 工具覆盖率"这个指标怎么理解?怎么提升?
系统设计
- 设计一个能跑 7×24 小时的自动化工作流,需要考虑哪些环节?
- 如何把一个"AI 半自动"流程升级到"全自动"?关键卡点在哪?
项目经验准备
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
