龙哥推荐理由:
继今年1月解读了阿里关于密集奖励对齐的DenseGRPO后,这次西湖大学&港中深带来的DrPO又玩出了新花样!它核心解决的是一个非常实际的问题:如何在不依赖奖励模型反向传播(即无需梯度)的情况下,高效地对单步文生图模型进行偏好对齐。这就像给模型请了一个不用付“过路费”的导师,直接通过样本间的“引力”和“斥力”来调整方向,省时省力效果还棒,尤其在处理巨型、不可微的奖励模型时优势巨大。科研价值和实用潜力都非常在线!
原论文信息如下:
论文标题:
Drifting Preference Optimization for One-Step Generative Models
发表日期:
2026年06月
发表单位:
西湖大学, 香港中文大学(深圳)
原文链接:
https://arxiv.org/pdf/2606.02535v1.pdf
项目链接:
https://ugvly.github.io/DrPO/
话说这两年,AI画图卷得飞起。从Midjourney到DALL·E,从Stable Diffusion到各种一步生成的Turbo模型,生成一张图的时间从几十秒压缩到了眨眼之间。特别是SD-Turbo、SDXL-Turbo这类单步生成模型(One-Step Generative Models),输入一个提示词,一次前向传播就直接出图,速度快到飞起,简直就是实时交互和边缘设备的福音。🤚
但是,速度快不代表效果好。这些一步生成模型虽然快,但生成的图片往往在审美偏好、构图细节、文本对齐等方面差点意思。于是,研究者们尝试用人类反馈(RLHF)或偏好优化来给模型“上上色”,让它更懂人类的喜好。然而,这里就出现了一个巨大的尴尬——标准的对齐方法,比如DPO、PPO,通常需要访问模型的策略概率、去噪轨迹,或者需要可微分的奖励函数来反向传播梯度。对于一步生成模型来说,这些东西要么算不了(没有明确的对数概率),要么算起来贵得要死(比如用一个大视觉语言模型当奖励模型,反向传播一次能让你等到花都谢了)。
可以这么说,一步生成模型的对齐问题,成了“爱恨纠葛”的中心:我们想要又快又好的图,但想要对齐偏好,就得牺牲速度或成本,两难全啊!
创新解法:无需梯度的“漂移”对齐术
西湖大学和香港中文大学(深圳)的研究者们最近提出了一种全新的方法——Drifting Preference Optimization(DrPO)。这名字不太好记,但它的思路极有创意:既然直接算奖励函数的梯度太贵或者不可能,那咱们就不算!咱们换一种方式——通过样本之间的“吸引力”和“排斥力”来隐式地模拟梯度。
DrPO的核心灵感源于漂移模型(Drifting Models)[Deng et al., 2026]。漂移模型是一种训练一步生成模型的非似然方法,它不需要显式的密度估计,而是通过在一个小批量样本中构造特征空间中的“漂移场”来指导模型更新。简单说,就是给每个生成样本算一个“移动方向”,让它朝着更好的样本“漂”过去,远离更差的样本。DrPO把这个思想从分布匹配(匹配真实数据分布)迁移到了偏好对齐(匹配人类偏好分布)。
具体是怎么做的呢?对于每个提示词(prompt),DrPO先从当前生成器中采样一批候选图像,然后用一个目标奖励模型(比如HPSv3、PickScore)对这些样本进行排序。接着,挑出得分高的样本作为“正样本”,得分低的作为“负样本”。再通过一个特征空间中的核函数(比如RBF函数),计算每个当前生成样本相对于这些正负样本的“偶极偏好场”(dipole preference field)。这个场会让生成的图像在特征空间中朝着高分样本拉近,远离低分样本。最关键的是,整个过程完全不需要对奖励模型求导,所以即使是超大模型或不可微的规则评分,都能轻松驾驭。
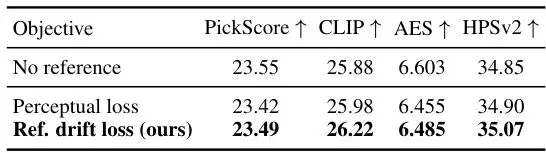
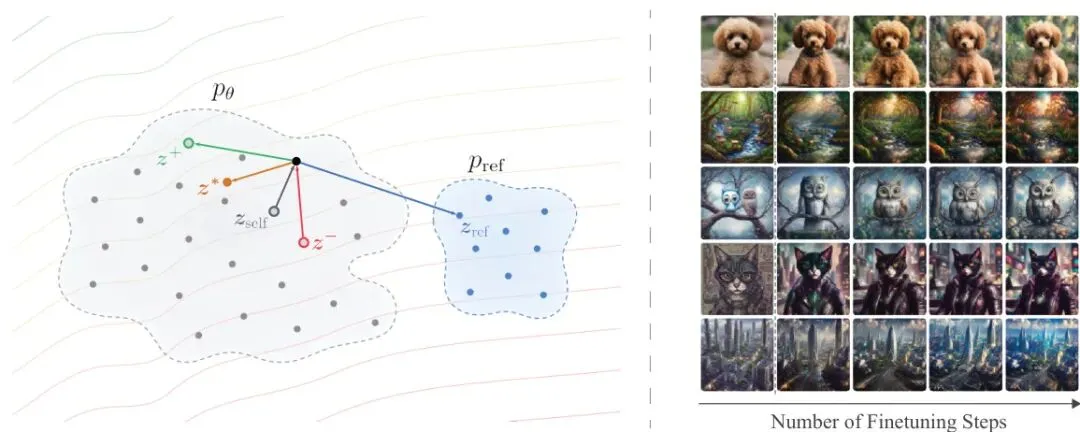 图1:DrPO概览。左图:微调网络时漂移场的构建。对于一个当前策略样本(黑色点),收集N个随机配对,奖励高的标记为正(红点),低的为负(蓝点)。结合p_θ和p_ref引起的自排斥与吸引力,合成最终回归目标z*(棕色点)。右图:固定测试提示在在线微调过程中的定性样本。
而且,DrPO还巧妙地引入了一个“参考漂移”项(reference drift),由一个冻结的基础生成器提供。这个参考漂移相当于一个正则化项,防止模型在优化偏好时偏离原始分布太远,保持了生成图片的多样性。
图1:DrPO概览。左图:微调网络时漂移场的构建。对于一个当前策略样本(黑色点),收集N个随机配对,奖励高的标记为正(红点),低的为负(蓝点)。结合p_θ和p_ref引起的自排斥与吸引力,合成最终回归目标z*(棕色点)。右图:固定测试提示在在线微调过程中的定性样本。
而且,DrPO还巧妙地引入了一个“参考漂移”项(reference drift),由一个冻结的基础生成器提供。这个参考漂移相当于一个正则化项,防止模型在优化偏好时偏离原始分布太远,保持了生成图片的多样性。
核心机制:偶极场+参考漂移,双剑合璧
偶极偏好场(Dipole Preference Field)
设当前生成器为 g_θ,输入噪声 ε 和条件 c,生成图像 x = g_θ(ε, c),然后通过一个固定的特征提取器 φ 得到特征 z = φ(x)。在训练迭代中,我们为同一个条件生成 K 个候选样本 x₁...x_K。然后用目标奖励 R 对它们排序,抽取 M 个奖励-有序对(reward-ordered pairs),形成正样本集 A⁺ 和负样本集 A⁻。接着,定义偶极奖励函数:
R_dipole(z) = exp(γ Σⱼ [k(z, a_j⁺) - k(z, a_j⁻)]),
其中 k 是一个特征空间的核函数(例如RBF),γ 是偶极强度。这个函数会对接近正样本的特征给予高值,对接近负样本的给予低值。对其求对数梯度,得到偏好场 V_pref:
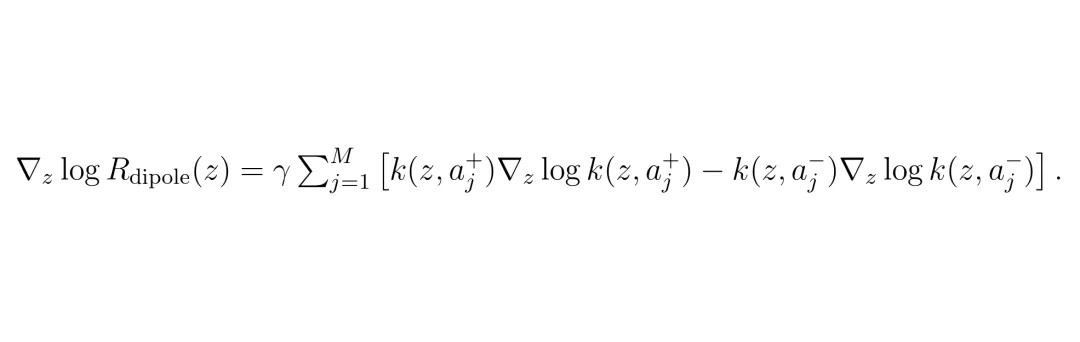 偶极偏好场的梯度表达式,通过核函数加权吸引正样本、排斥负样本。
这个场是局部的:远离所有样本的点几乎不受影响。这正好阻止了模型在缺乏证据的区域瞎猜。
在经典RLHF中,我们有一个参考分布 q_ref 来防止模型走偏。DrPO 中用了一个冻结的基础生成器 g_ref(通常是训练前的原始模型)。我们从 g_ref 采样同样的噪声,得到参考特征集 R。然后类似地构造参考漂移 V_ref,使当前生成器的特征分布不至于跟参考分布差得太远。最终的目标漂移场为:
V_DrPO(z_i) = V_pref(z_i) + λ V_ref(z_i),
然后给每个当前特征加上一个比例系数 η,并停止梯度,得到回归目标 z_i^* = sg(z_i + η V_DrPO(z_i))。
偶极偏好场的梯度表达式,通过核函数加权吸引正样本、排斥负样本。
这个场是局部的:远离所有样本的点几乎不受影响。这正好阻止了模型在缺乏证据的区域瞎猜。
在经典RLHF中,我们有一个参考分布 q_ref 来防止模型走偏。DrPO 中用了一个冻结的基础生成器 g_ref(通常是训练前的原始模型)。我们从 g_ref 采样同样的噪声,得到参考特征集 R。然后类似地构造参考漂移 V_ref,使当前生成器的特征分布不至于跟参考分布差得太远。最终的目标漂移场为:
V_DrPO(z_i) = V_pref(z_i) + λ V_ref(z_i),
然后给每个当前特征加上一个比例系数 η,并停止梯度,得到回归目标 z_i^* = sg(z_i + η V_DrPO(z_i))。
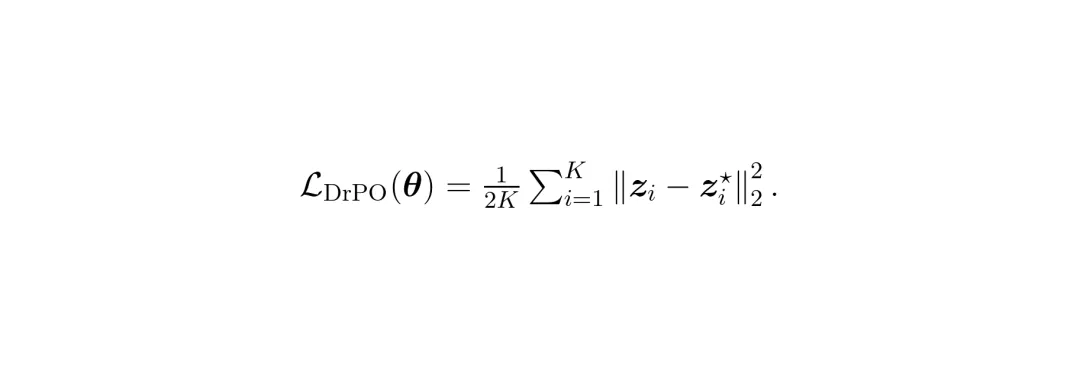 DrPO的最终损失函数:让模型特征逼近由漂移场引导的目标特征。
整个流程就像给每个样本配了一个“指南针”,指往更好方向,还配了一个“锚”,保证不跑太远。而且,这个指南针完全不依赖奖励模型的梯度,所以那些超大、不可微、或者需要大量计算的奖励模型(比如HPSv3、GenEval规则评分)都能直接用。
DrPO的最终损失函数:让模型特征逼近由漂移场引导的目标特征。
整个流程就像给每个样本配了一个“指南针”,指往更好方向,还配了一个“锚”,保证不跑太远。而且,这个指南针完全不依赖奖励模型的梯度,所以那些超大、不可微、或者需要大量计算的奖励模型(比如HPSv3、GenEval规则评分)都能直接用。实验鉴真金:效果与效率的双重胜利
理论再漂亮,也得看实战。DrPO 在 SD-Turbo 和 SDXL-Turbo 两个一步生成模型上进行了测试,对比了多种方法,包括需要奖励梯度的 DRaFT、VGG-Flow1-step,以及不需要梯度的一步DPO、PSO、GRPO等。
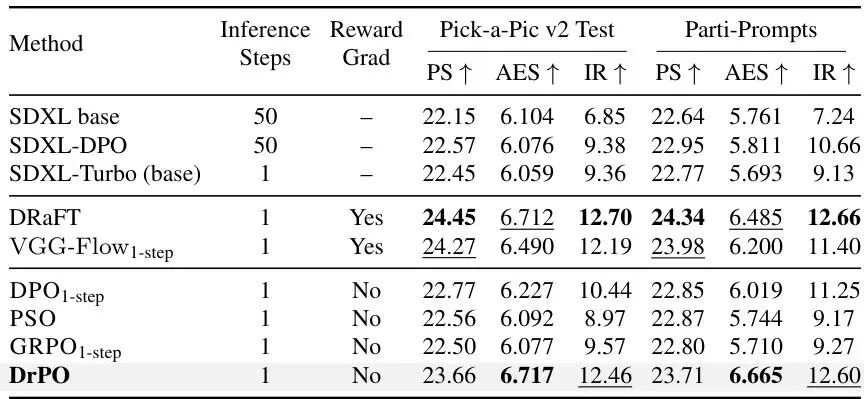
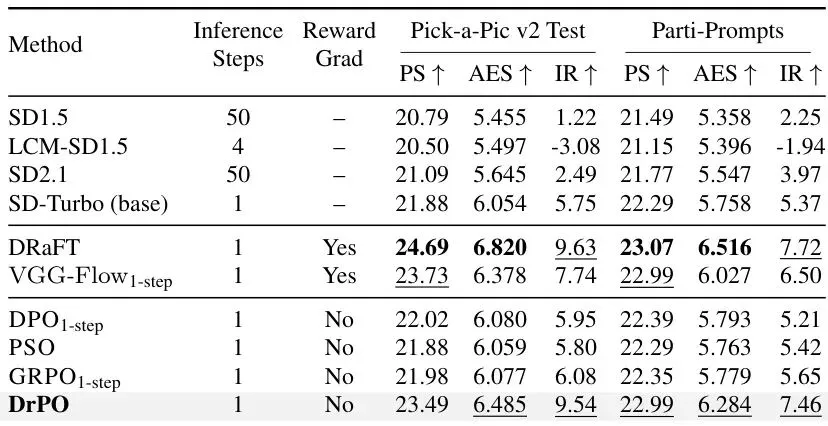
可以看到,DrPO 在不需要奖励梯度的情况下,在 Pick-a-Pic v2 测试集上将 PickScore(PS)从基线的 22.45 提升到了 23.66,Aesthetics(AES)从 6.059 提升到 6.717,ImageReward(IR)从 9.36 提升到 12.46。这个提升幅度在无梯度方法中是最高的,甚至接近了需要梯度的 DRaFT(24.45/6.712/12.70)。考虑到 DRaFT 需要对奖励模型反向传播,这个成绩相当亮眼。
同样,DrPO 在无梯度方法中领先,提升了 PickScore 从 21.88 到 23.49,AES 从 6.054 到 6.485,IR 从 5.75 到 9.54。
除了这些标量指标,论文还使用了 Qwen3-VL 作为外部 VLM 裁判,进行成对偏好评估。结果如图2所示,DrPO 生成的图像在两个测试集上都被 VLM 显著偏好(红色条表示 DrPO 偏好,蓝色条为对比方法偏好):
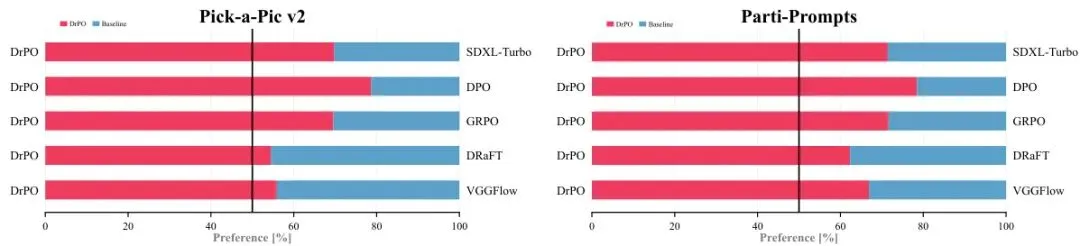 图2:Qwen3-VL成对偏好评估。红色为DrPO偏好,蓝色为对比基线偏好。
更让人惊喜的是效率。当使用 HPSv3 这种大型 VLM 奖励模型时,DrPO 将每次更新的时间从基线(DRaFT)的 21.62 秒降低到了 6.17 秒,获得了 3.51 倍的加速!这是因为 DrPO 完全去掉了奖励模型的反向传播。
图2:Qwen3-VL成对偏好评估。红色为DrPO偏好,蓝色为对比基线偏好。
更让人惊喜的是效率。当使用 HPSv3 这种大型 VLM 奖励模型时,DrPO 将每次更新的时间从基线(DRaFT)的 21.62 秒降低到了 6.17 秒,获得了 3.51 倍的加速!这是因为 DrPO 完全去掉了奖励模型的反向传播。
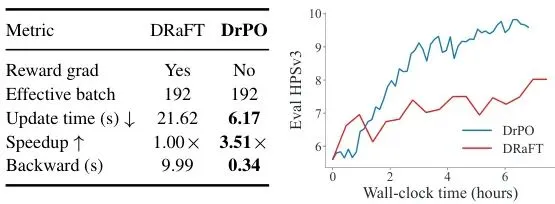 图5:HPSv3训练效率对比。DrPO去除奖励模型反向传播,加速3.51倍。
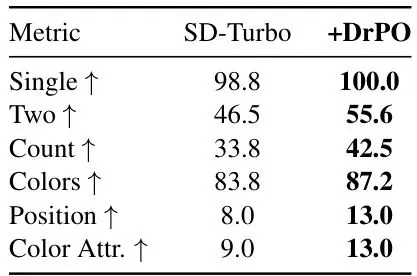
此外,DrPO 还能直接处理不可微的奖励,比如 GenEval 的组合性评分(对象存在、计数、颜色、位置等)。表3显示,在几乎所有子任务上,DrPO 都带来了提升。
图5:HPSv3训练效率对比。DrPO去除奖励模型反向传播,加速3.51倍。
此外,DrPO 还能直接处理不可微的奖励,比如 GenEval 的组合性评分(对象存在、计数、颜色、位置等)。表3显示,在几乎所有子任务上,DrPO 都带来了提升。
稳与省:消融实验揭示的设计秘诀
DrPO 论文进行了大量的消融实验,揭示了各个设计选择的影响。
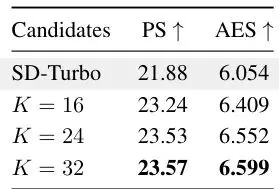
如表4(a)所示,当每批次候选数量 K 从16增加到32时,PickScore 和 AES 持续上升(PS从23.24到23.57,AES从6.409到6.599)。更大的候选池提供了更稳定的成对估计,使漂移场更可靠。
表4(b)显示,使用 latent-MAE 特征(来自漂移模型的预训练编码器)效果最好,而直接使用 VAE 的原始潜变量特征会导致严重退化(PS降到20.52,AES降到4.543)。这说明漂移场需要一个语义丰富且各向同性的特征空间。DINOv2 特征也有效,但略逊于 latent-MAE。
表4(c)和4(d)表明,不同核函数(余弦、RBF、指数、拉普拉斯)下性能稳定;速度尺度η在一定范围内(β=1000到10000)性能波动不大,说明方法对超参数不敏感,容易调。表5对比了不使用参考、使用感知损失(LPIPS)和 DrPO 的参考漂移。参考漂移在 CLIP、HPSv2 等指标上表现更好,且能更好地平衡多样性和对齐度。
通过消融实验,可以确认 DrPO 的设计是目前最优组合:使用 latent-MAE 特征、RBF 核函数、适中的速度尺度,并启用参考漂移。
总结与展望:一步对齐的未来在“漂移”
DrPO 的出现,为一步生成模型的偏好对齐提供了一条新思路。它巧妙地将“漂移模型”的思想与偏好排序结合,完全避开了奖励模型的反向传播,极大地拓宽了可使用的奖励模型范围(包括那些超大、不可微的)。而且训练效率极高,做到了又快又好。
当然,它也有局限。目前的方法高度依赖特征提取器 φ 的质量。如果 φ 不能捕捉到我们真正关心的属性(比如精确的物体计数、复杂的空间关系、精细的字体识别等),那么漂移场可能会在特征空间里很平滑,但在实际偏好上错位。未来的工作可以尝试设计自适应的特征提取器,或者融合多个特征源来提升鲁棒性。
另外,论文初步探索了离线版本的 DrPO,即不再在每次迭代中在线采样和排序,而是利用固定的偏好对数据集来构造漂移场。初步结果显示这种方法也能提升性能,但空间还很大。如果离线 DrPO 能被充分开发,那么将极大降低训练成本,让高质量对齐变得更加普及。
龙迷三问
DrPO 与 DPO 本质区别是什么?DPO 通过优化策略与参考策略之间的对数概率比来隐式地拟合偏好,它需要知道生成图片的概率(似然)。对于一步生成模型,这个概率难以计算,所以 DPO 的一步变种效果很差。DrPO 完全避开了概率,转而使用特征空间中的几何关系(吸引/排斥)来直接构造更新方向。顺带一提,DPO 的英文全称是 Direct Preference Optimization(直接偏好优化),DrPO 是 Drifting Preference Optimization(漂移偏好优化)。
“漂移模型”和“漂移偏好优化”是什么关系?漂移模型(Drifting Models)是 Deng et al. 2026 年提出的一种训练一步生成模型的方法,通过小批量样本构造特征空间的漂移场来实现分布匹配。DrPO 借用了这个框架,但是把目标从“匹配数据分布”改为了“匹配偏好分布”——即用奖励模型排序构造正负样本,形成偏好漂移场。所以 DrPO 可以看作是漂移模型在偏好对齐领域的应用和扩展。
DrPO 能不能用于多步扩散模型?论文专注于一步生成模型,但核心思想(在特征空间中构建偏好漂移场)原则上可以扩展到多步模型。不过多步模型有去噪轨迹,可能会有更高效的直接方法(比如 Diffusion-DPO)。DrPO 的真正优势在于“无需奖励梯度”,这在一步模型上体现最明显。如果要用于多步,可能需要调整参考漂移的构造方式。
如果你还有哪些想要了解的,欢迎在评论区留言或者讨论~龙哥点评
论文创新性分数:★★★★☆(4颗星)
将漂移模型的框架引入偏好对齐,提出“偶极场+参考漂移”的无梯度优化范式,思路新颖,与现有方法有本质区别。实验合理度:★★★★☆
实验设计全面,涵盖了多种模型、多种奖励、多种基线和消融。对比方法包含需要梯度与无需梯度的两大类,公平性较好。唯一的小瑕疵是离线实验还比较初步。学术研究价值:★★★★★
开创了一种不依赖梯度的一步生成模型对齐方法,对后续研究(尤其是低资源、大规模奖励场景)有重要启发。参考漂移项的设计也为分布控制提供了新视角。稳定性:★★★★☆
在 SD-Turbo 和 SDXL-Turbo 上都能稳定提升,消融显示对超参数不敏感。但稳定性仍然受到特征提取器质量的影响,换用不同的特征提取器可能表现不稳定。适应性以及泛化能力:★★★★☆
在两种不同架构、不同潜空间的一步生成模型上都有效,对不同奖励模型(PickScore、HPSv3、AES、IR、GenEval)均适用,泛化能力较强。但一步生成模型的多样性在此类方法中可能受损,论文未充分讨论。硬件需求及成本:★★★★★
无需奖励梯度,训练速度极大提升;推理时依然是单次前向传播,完全不加量。硬件需求与原始一步生成模型相同。复现难度:★★★★☆
论文提供了算法伪代码和详细的超参数设置,代码和项目已开源,复现较容易。不过离线部分目前只有概念性结果,全量复现有一定的工程适配工作。产品化成熟度:★★★☆☆
用于快速、低成本的偏好微调非常有前景,但产品化还需解决:①特征提取器的选择与维护;②对超出概念外的奖励(如精确计数)效果可能有限;③在线采样带来的额外延迟。目前更适合作为研究或内部工具。可能的问题:论文对离线DrPO的探索过于初步,没有展示出超越在线版本的优势。另外,未讨论在优化过程中多样性(FID等指标)的变化,仅关注对齐指标,可能存在一定程度的多样性下降。[1] Deng et al., "Drifting Models: Likelihood-Free Training of One-Step Generative Models", arXiv 2026.[2] Sauer et al., "Adversarial Diffusion Distillation", ECCV 2024.[3] Clark et al., "Direct Reward Fine-Tuning for Diffusion Models", NeurIPS 2024.[4] Rafailov et al., "Direct Preference Optimization", NeurIPS 2023.[5] Ma et al., "Human Preference Score v3", arXiv 2025.[6] Ghosh et al., "GenEval: A Benchmark for Compositional Text-to-Image Generation", 2023.论文原文:https://arxiv.org/pdf/2606.02535v1.pdf项目页面:https://ugvly.github.io/DrPO/*本文仅代表个人理解及观点,不构成任何论文审核或者项目落地推荐意见,具体以相关组织评审结果为准。欢迎就论文内容交流探讨,理性发言哦~ 想了解更多原文细节的小伙伴,可以点击左下角的"阅读原文",查看更多原论文细节哦!
🐉 本周星球独家(真实样本):
📰 资讯:人工智能:加速向未来_学信网 | chsi.com.cn | 时间未知
💼 招聘:OpenAI机器人岗位硬件招聘:全栈硬件、运营、系统及机器学习…
📚 论文:自蒸馏绕过似然黑洞!GDSD让扩散语言模型RL训练更稳,规划任务提升+…
星球过去 7 天共更新 246 条干货,这只是冰山一角:
👇 扫码加入「龙哥读论文」知识星球,每天打开像刷视频一样轻松


告别“梯度依赖”,DrPO让AI画出你心中所想!
想和龙哥一起探讨大模型、图像生成的前沿技术吗?
欢迎加入龙哥读论文粉丝群,
扫描下方二维码或者添加龙哥助手微信号加群:kangjinlonghelper。
一定要备注:研究方向+地点+学校/公司+昵称(如 图像生成+上海+西湖大学+小龙),根据格式备注,可更快被通过且邀请进群。