《IEEE TMI》IF=9.8|深圳大学罗笑玲教授成果:让资料不齐的AD多模态诊断跑起来:MRI、PET、CSF缺一项,模型还能怎么判断?
在记忆门诊或阿尔茨海默病研究队列里,理想情况是每位受试者都有结构MRI、PET、脑脊液标志物和完整认知量表。但现实常常不是这样:PET有费用和辐射顾虑,CSF检查有侵入性,部分量表或随访数据也可能缺失。对临床医生来说,这是日常资料不齐;对AI模型来说,却可能是输入结构被打乱。
罗笑玲教授等来自深圳大学、香港理工大学、香港人工智能设计实验室和中国海洋大学的团队,在IEEE Transactions on Medical Imaging接收稿中提出了HI-AD框架。该研究尝试回答一个更贴近真实流程的问题:当多模态资料天然缺项时,模型能否仍然稳定利用现有信息?

01 /【第一部分:推文概览(这篇论文做了什么)】
这篇研究做了一个面向“不完整多模态”的阿尔茨海默病诊断模型,让MRI、PET、CSF和临床评估数据在缺失情况下仍能参与诊断决策。
数据方面,论文使用ADNI队列,包括ADNI-1、ADNI-GO、ADNI-2和ADNI-3四个子集。按表I合计,ADNI共2335例受试者,模态包括T1加权结构MRI、18F-AV45淀粉样蛋白PET、CSF中的Aβ42、total tau、phosphorylated tau,以及29项临床或神经心理评估变量。作者还使用AIBL数据库做验证,表I合计334例,包含MRI灰质图像和PET两种影像模态。
与许多“先补全缺失模态”的方法不同,HI-AD不试图凭空生成缺失的PET或CSF。它走的是imputation-free路线,也就是“有什么资料就处理什么资料”。论文在ADNI上随机遮蔽MRI、PET和CAD,缺失率设为10%、30%、50%,并保证每个受试者至少有一个模态可用;CSF由于本身不完整,保留1317个可用样本。AIBL中,MRI被视为完整模态,PET按固定缺失率遮蔽。
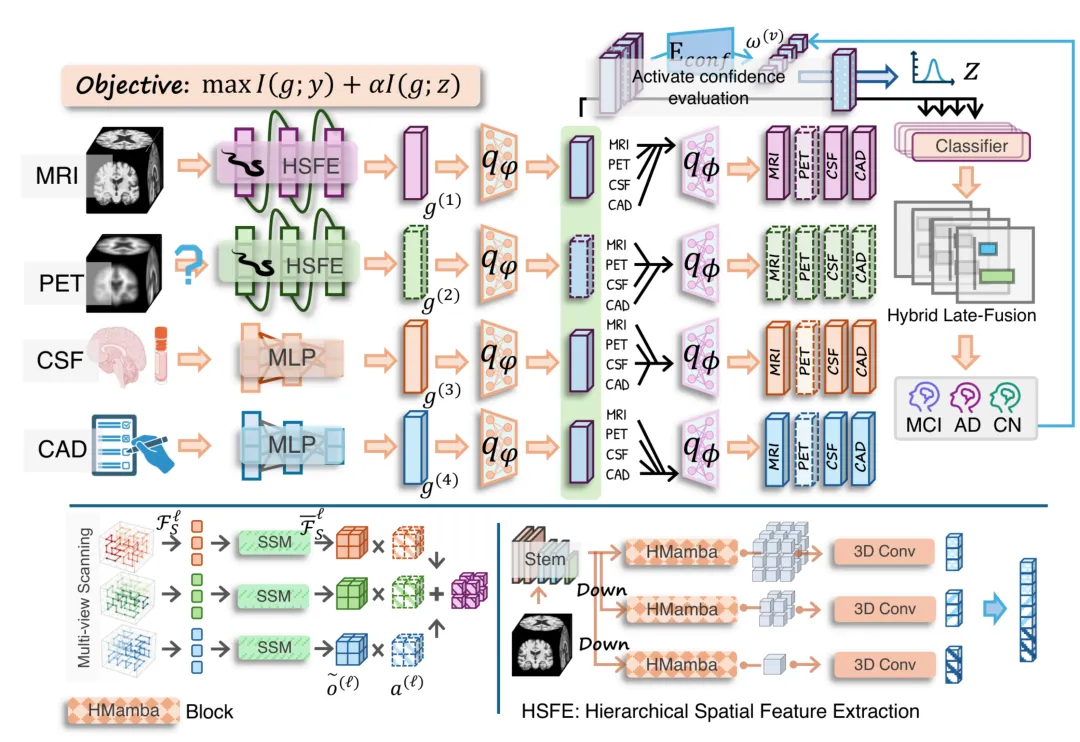
图2(HI-AD整体框架图,左侧为各模态特征提取,右侧为多模态语义编码与融合)
图注:HI-AD的核心思路是先分别理解每类资料,再根据模态可用性和置信度进行融合。
02 /【第二部分:核心创新点】
用多视角Hilbert曲线配合Mamba来读取3D脑影像。
第一个创新,是用多视角Hilbert曲线配合Mamba来读取3D脑影像。
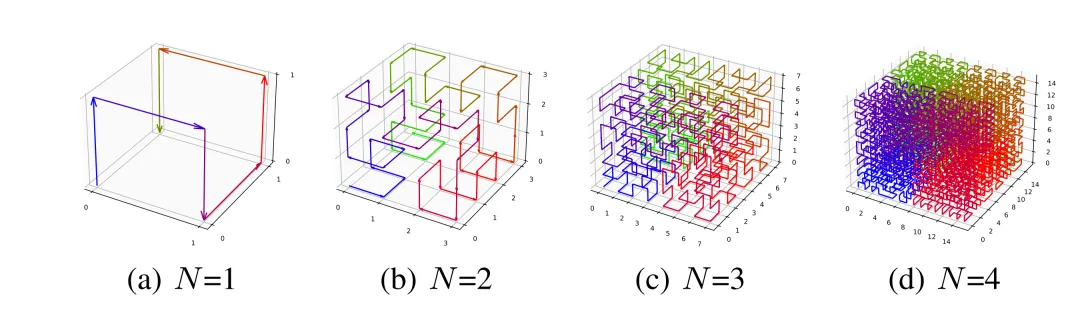
这里的技术细节较深,核心思路可以这样理解:3D脑影像不能直接丢给序列模型,需要先像“走迷宫”一样把体素排成一条序列。普通横扫或折返扫描容易把解剖上相邻的体素拉得很远,像把一张脑图切开后又错位排队。Hilbert曲线的作用,是尽量让三维空间中相邻的体素,在一维序列中也保持接近。
作者进一步使用多视角Hilbert扫描,并用体素级动态权重融合不同扫描方向。论文表VI显示,在ADNI的MCI vs CN、50%缺失率任务中,完整HI-AD的AUC为0.848;去掉HMamba后降至0.818,改用普通3轴扫描或cross scanning时AUC分别为0.806和0.803。这说明这部分设计不是装饰,而是直接影响早期区分任务的影像表征质量。
图1(不同阶数的3D Hilbert空间填充曲线示意)
图注:Hilbert曲线试图在“摊平”3D脑影像时尽量保留空间邻近关系。
层级空间特征提取HSFE。
作者也承认,Hilbert扫描不能完全避免空间撕裂,尤其在高阶情况下。因此HI-AD没有只依赖单层序列建模,而是把残差3D卷积和HMamba放在多级结构里,逐层扩大感受野。临床类比一下,它不是只看一个层面的脑区变化,而是从局部纹理到跨区域关系逐级汇总。
消融实验同样支持这一点:在同一MCI vs CN、50%缺失率任务中,去掉HSFE后AUC为0.814,把HSFE改成单层后AUC为0.812,均低于完整HI-AD的0.848。
用主动置信度评估来决定“听谁多一点”。
多模态诊断有点像会诊。MRI、PET、CSF、量表都能提供信息,但每位患者手里哪项资料更可靠,不一定相同。如果模型过早偏向容易拟合的模态,其他模态可能训练不足,论文称之为modality collapse。HI-AD通过互信息驱动的目标函数、动态MoE中层融合和hybrid late-fusion,让每个模态既保留自身信息,又在最终判断时按置信度分配权重。
表IX中,在ADNI的MCI vs CN、30%缺失率下,完整HI-AD AUC为0.891;去掉主动置信度评估后为0.884,去掉预测置信度分支后为0.886。表VIII还显示,在50%缺失率下去掉late-fusion后AUC为0.809,明显低于完整模型的0.848。
03 /【第三部分:关键结果】
结果部分不需要堆满表格,抓三点就够。
第一,在最贴近早期筛查难点的MCI vs CN任务中,50%模态缺失时,HI-AD取得AUC 0.848±0.005、ACC 0.737±0.020。对应最强基线HAD的AUC为0.838±0.018、ACC为0.732±0.028。这个对比说明,在资料缺一半的设定下,HI-AD在早期区分任务上仍有小幅但稳定的优势。
第二,在相对更容易的AD vs CN任务中,同样50%缺失率下,HI-AD的AUC为0.973±0.015、ACC为0.918±0.018;HAD对应为AUC 0.967±0.006、ACC 0.913±0.005。作者在表II到表IV中报告了10%、30%、50%三档缺失率,并用BH-FDR校正后的q值与最强基线比较。
第三,单模态对比提醒我们不要低估临床评估变量。表VII中,在ADNI全模态MCI vs CN任务上,CAD单模态已经达到AUC 0.946±0.013,是最强单模态;HI-AD多模态融合后为AUC 0.964±0.013、ACC 0.902±0.008。这个结果支持多模态互补,但也引出后面必须讨论的局限。
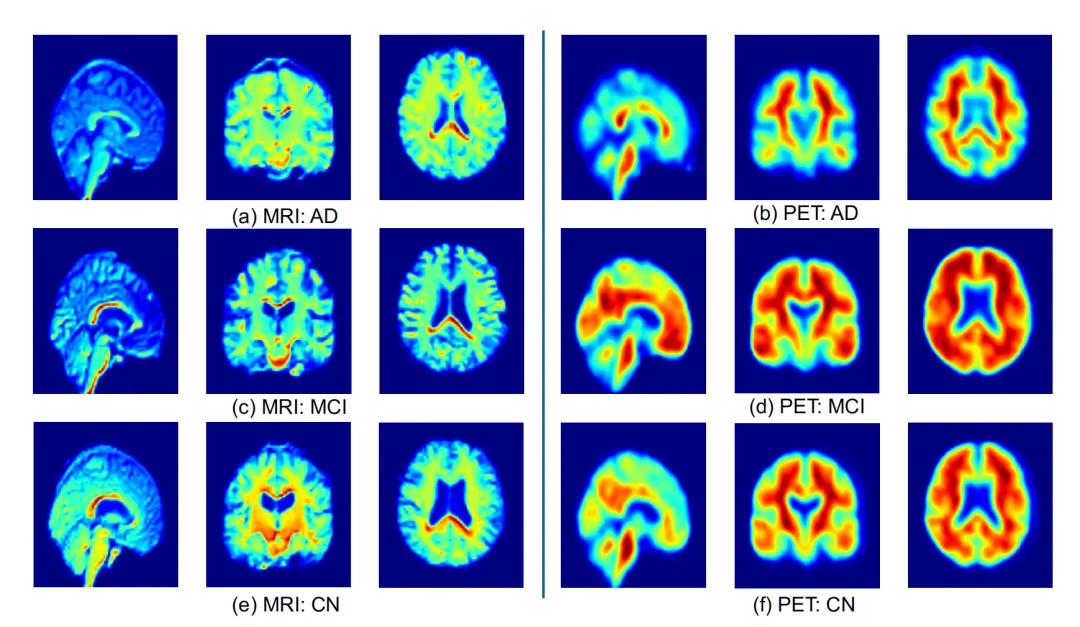
图5(MRI和PET的token-to-voxel Grad-CAM显著性图)
图注:模型的影像注意区域被映射回3D空间,用于观察MRI和PET特征是否集中在有诊断信息的脑区。
04 /【第四部分:复现与务实讨论】
复现门槛方面,原文未提及HI-AD的代码仓库、模型权重或完整复现实验脚本是否开放。数据来自ADNI和AIBL数据库,但原文未明确说明数据访问权限或下载流程。预处理依赖SPM进行PET到MRI配准和MNI空间归一化,使用FreeSurfer进行MRI/PET去颅骨,最终重采样到128×128×128。算力方面,原文说明所有实验运行在Ubuntu 20.04和单张RTX 4090上;表X中HI-AD在ADNI任务的参数量为47.56M,FLOPs为65.9G。
也就是说,普通课题组可以跟进思路,但严格复现并不轻。至少需要可申请到的ADNI/AIBL数据、规范影像预处理流程、GPU资源,以及自行实现模型的工程能力。
局限性中,作者明确提醒了一个关键点:CAD模态包含CDRSB、MMSE、ADAS、FAQ、MOCA、mPACC等与ADNI临床诊断流程密切相关的认知和功能评估变量。虽然标签来自官方ADNI标注,而不是直接由这些变量手工推导,但作者认为不能完全排除标签接近性或部分循环性,因此包含CAD的模型绝对性能可能被高估。
从方法和数据角度看,还有两点需要务实看待:ADNI上的缺失是随机模拟遮蔽,并不一定等同真实医院中“为什么没做PET、为什么没有CSF”的机制;此外,论文没有提供前瞻性临床验证、读片医生对照或真实SOP嵌入实验。
所以,这篇工作的临床距离可以这样概括:它为医学AI处理“不完整多模态资料”提供了一个清晰方向。对做科研的临床团队来说,更现实的启发是:不要只在“资料最齐”的小样本上建模,也要正面设计资料缺失时模型如何工作、如何分配证据权重。
— END —