北大深圳研究生院提出DSFedMed:基于基础模型与轻量级模型互蒸馏的双尺度联邦医疗图像分割
- 2026-07-08 00:46:05


标题: DSFedMed:基于基础模型与轻量级模型互蒸馏的双尺度联邦医疗图像分割代码地址: https://github.com/LMIAPC/DSFedMed导读
医疗图像分割的联邦学习场景中,基础模型虽精度高但部署成本高昂,轻量级模型虽高效却泛化不足。基于此,论文提出 DSFedMed 双尺度联邦框架,创新性地实现服务器端基础模型(SAM)与客户端轻量级模型(TinySAM)的协同训练。该框架通过 ControlNet 生成高质量医疗合成数据,规避隐私数据共享难题,再经可学习性引导的互知识蒸馏,动态筛选高价值样本实现双向知识传递。实验表明,DSFedMed 在眼底、前列腺等 5 个医疗数据集上,平均 Dice 系数较 FedSAM 提升 2%,同时通信成本与推理时间降低近 90%,完美平衡精度与效率。这项研究为资源受限、隐私敏感的医疗联邦场景,提供了基础模型落地的可行方案,具有重要的临床应用价值。
预备知识
联邦学习(FL):分布式学习范式,数据分散在客户端,模型训练时不集中原始数据,仅通过参数传递聚合知识,符合医疗数据隐私法规(如GDPR、CCPA)。
基础模型(FMs):预训练于大规模数据的通用模型(如SAM、ViT),泛化能力强,但参数量大、计算成本高。
轻量级模型:小型化模型(如TinySAM、U-Net),参数量少、推理快速,适配资源有限的客户端,但泛化能力较弱。
知识蒸馏(KD):通过教师模型向学生模型传递知识提升性能,本文扩展为双向互蒸馏。
ControlNet+Stable Diffusion:ControlNet 可对扩散模型施加结构约束,结合 Stable Diffusion 生成可控、高保真的合成数据。
关键指标:Dice 系数(分割精度)、IoU(交并比)、通信开销(MB)、推理时间(s)、FID(生成数据分布相似度)、FLD(生成数据新颖性)。
研究动机
基础模型的联邦部署困境:SAM等基础模型在医疗联邦场景中面临三大问题 —— 计算资源需求远超临床客户端能力、模型参数传输导致通信开销巨大、推理 latency 长(图 1 显示 FedSAM 推理时间 0.118s,通信开销 71538MB)。
轻量级模型的精度短板:FedU-Net 等轻量级模型虽高效(推理时间 0.007s),但因缺乏全局泛化知识,分割精度不足(平均 Dice 仅 0.732),难以满足医疗诊断需求。
核心挑战:① 如何在资源受限的分布式环境中融合基础模型的泛化能力与轻量级模型的效率;② 医疗数据隐私限制下,缺乏真实公共数据集支撑跨模型知识传递;③ 异尺度模型(基础模型 vs 轻量级模型)的知识对齐需高效样本选择机制。

图 1 是联邦分割方法在通信成本与Dice 性能上的对比散点图,气泡大小直观反映模型推理时间。横轴为总通信开销(单位 MB),纵轴为衡量分割精度的 Dice 系数,清晰呈现不同方法的性能 - 效率权衡。
基础模型类方法(如 FedSAM)虽 Dice 系数较高、精度出色,但通信开销极大(超 70000MB),且气泡大、推理时间长(0.118s),部署成本高;轻量级模型(如 FedU-Net)气泡小、推理快(0.007s)、通信开销低(约 2430MB),但纵轴位置低、精度不足。
而 DSFedMed(本文方法)实现了最优平衡:Dice 系数比 FedSAM 等基础模型类方法高 2%,通信开销却降低近 90%,且推理时间(0.015s)与轻量级模型相当,气泡大小适中,完美兼顾了医疗图像分割所需的高精度与资源受限场景下的部署效率。
创新点
双尺度联邦知识迁移框架:首次实现服务器端基础模型(SAM)与客户端轻量级模型(TinySAM)的协同训练,兼顾高精度与低部署成本(图 2)。
模态自适应医疗图像生成器:基于 ControlNet 构建合成数据生成 pipeline,无需真实数据即可生成符合全局分布的医疗图像 - 掩码对(公式 1-2),解决隐私约束下的知识蒸馏数据缺失问题。
可学习性引导的互知识蒸馏机制:通过融合 GT 损失与双向 KL 散度设计样本评分函数(公式 6),动态选择高信息样本(图 3-4),实现基础模型向轻量级模型传递泛化知识、轻量级模型向基础模型注入领域知识的双向增强。
方法
DSFedMed 框架核心分为三大组件(图 2):可控医疗图像生成、双尺度模型协同训练、可学习性引导互蒸馏,整体流程为 “合成数据搭桥→双模型并行训练→双向知识蒸馏”。
4.1框架概述(图 2)
服务器端:部署基础模型SAM(ViT-B/16),负责全局知识聚合、合成数据生成与互蒸馏主导。
客户端:每个客户端部署轻量级模型 TinySAM 与可训练的 ControlNet 模块,冻结 Stable Diffusion 主干,仅通过本地私有数据微调 ControlNet,实现个性化数据生成。
核心逻辑:客户端上传 ControlNet 参数→服务器生成全局合成数据集→双模型基于合成数据进行互蒸馏→迭代优化模型性能。
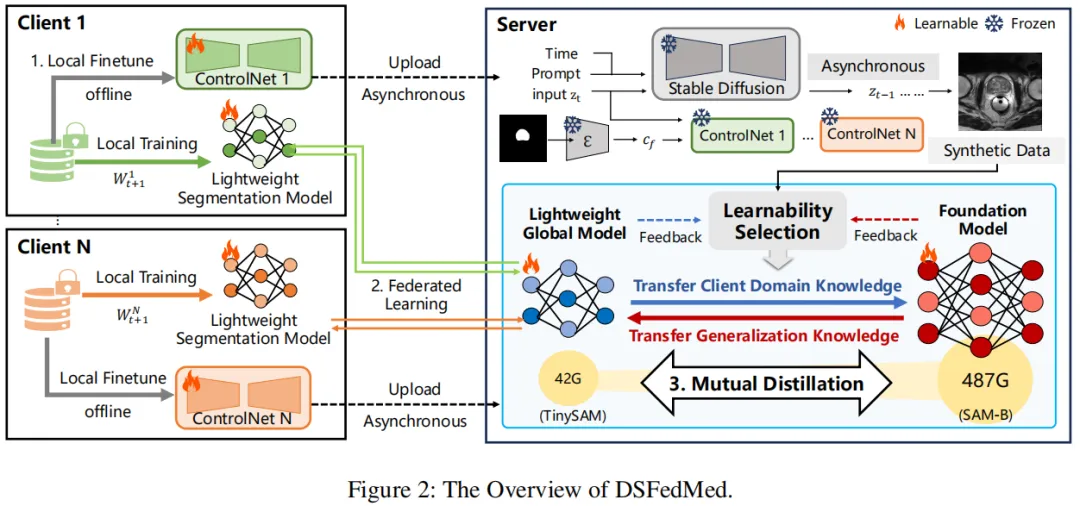
图 2 是 DSFedMed 双尺度联邦医疗图像分割框架的整体流程图,清晰呈现了服务器与多个客户端间异步协同的三大核心环节,直观展现 “合成数据搭桥 - 双模型并行训练 - 双向知识蒸馏” 的完整逻辑。
框架分为服务器和客户端两大主体:客户端部署轻量级分割模型 TinySAM 与可训练的ControlNet 模块,Stable Diffusion 主干保持冻结;服务器则部署基础模型 SAM(SAM-B),负责全局协调与知识聚合。
流程上,首先客户端利用本地私有医疗数据微调ControlNet,仅上传轻量化的 ControlNet 参数(避免敏感数据传输),此为 “本地微调 - 上传” 阶段;接着服务器收集所有客户端的ControlNet 参数,生成融合各客户端模态特征的全局合成数据集,同时通过联邦平均聚合客户端 TinySAM 的参数,形成全局轻量级模型,SAM 则基于合成数据微调,完成 “联邦学习 - 知识初步对齐”;最后,服务器借助合成数据开展可学习性引导的互蒸馏,SAM 向 TinySAM 传递泛化知识,TinySAM 向 SAM 注入领域特异性知识,实现双模型双向增强,且全程采用异步模式,客户端无需持续在线。
图中还标注了模型规模差异(TinySAM 42G、SAM-B 487G),凸显双尺度设计的核心思路,即通过轻量化客户端适配资源约束,依托服务器端基础模型保障精度,最终达成高效且高精度的联邦分割。
4.2高效数据生成(Efficient Data Generation)
目标:生成高保真、模态自适应的医疗图像-掩码对,替代真实数据支撑蒸馏。
4.3双尺度模型的协同训练(Collaborative Training of Dual-Scale Model)
实现服务器端SAM与客户端TinySAM的并行训练与知识初步对齐。
4.4可学习性引导的互知识蒸馏(Learnability-Guided Mutual Distillation)
核心模块,实现双尺度模型的双向知识增强,对应图3(蒸馏流程)与图4(样本选择示例)。
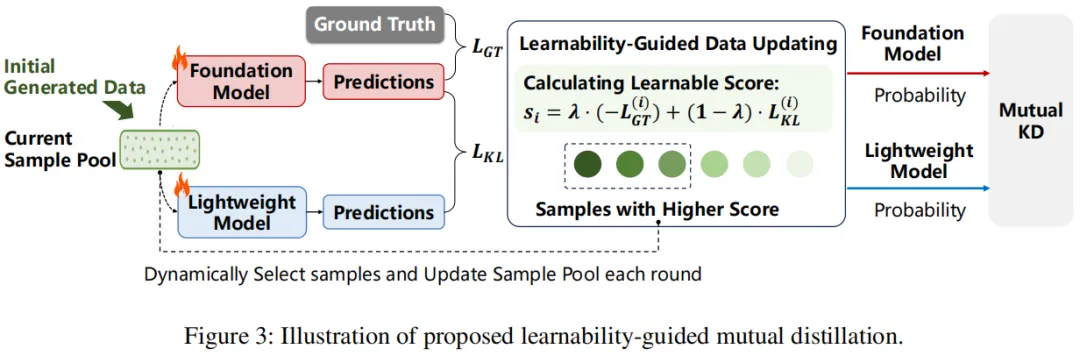
图 3 是可学习性引导的互知识蒸馏流程示意图,核心展示如何从生成数据中筛选高价值样本,实现服务器端 SAM 与客户端 TinySAM 的双向知识传递。
流程以初始生成数据集为起点,两大模型分别对样本做出预测并输出概率分布。关键环节是计算可学习性评分(对应公式 6):融合 SAM 预测与真值的 GT 损失(保障样本监督可靠性)和两模型预测的双向 KL 散度(捕捉模型分歧,凸显知识互补价值)。
随后按评分动态筛选高价值样本更新样本池,每轮训练都会刷新,确保蒸馏聚焦于最具信息量的样本。通过这种方式,SAM 向 TinySAM 传递泛化知识,提升轻量模型的全局适配能力;TinySAM 则将客户端领域知识反向注入 SAM,助力基础模型优化,整个过程形成闭环互促,高效实现双尺度模型的知识对齐。
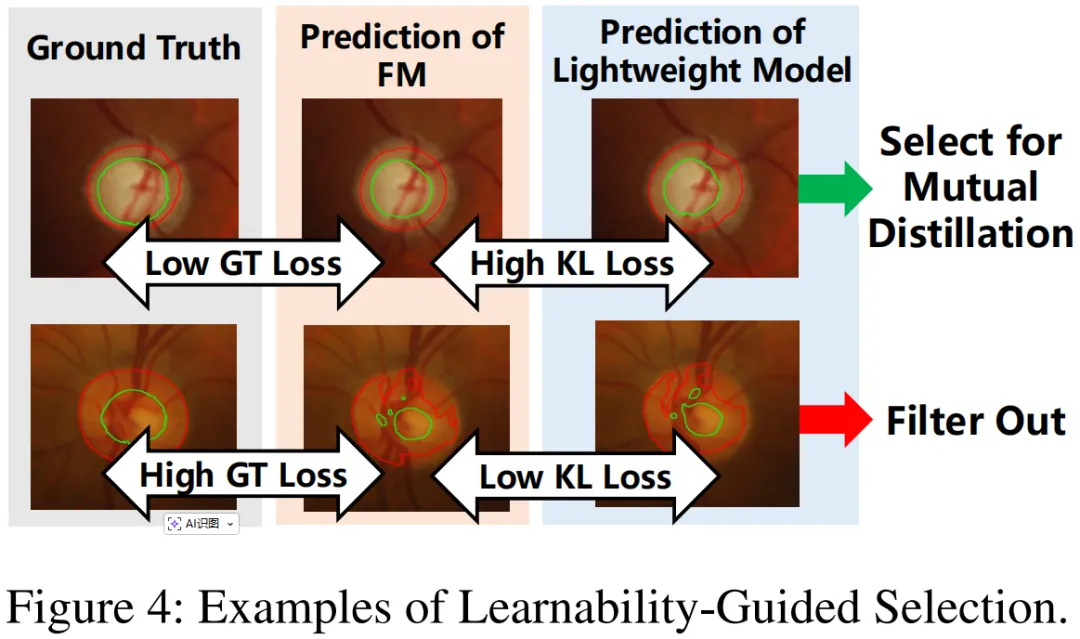
图 4 是可学习性引导样本选择的直观示例,核心展示哪些生成样本会被纳入互蒸馏、哪些会被过滤,呼应图 3 的评分逻辑。
图中清晰划分两类样本:左侧 “低 GT 损失 + 高 KL 损失” 的样本被选中用于互蒸馏 —— 低 GT 损失意味着 SAM 对该样本的预测与真值贴合,监督可靠;高 KL 损失表示 SAM 与 TinySAM 的预测分歧大,这类样本能填补两模型的知识缺口,是双向知识传递的关键。
右侧 “高 GT 损失 + 低 KL 损失” 的样本则被过滤 —— 高 GT 损失说明样本监督可靠性差,低 KL 损失表明两模型预测无明显分歧,缺乏知识互补价值,纳入后反而可能干扰蒸馏效果。
该图具象化了样本选择的核心准则,即优先筛选 “监督可靠且分歧显著” 的高价值样本,确保互蒸馏聚焦有效知识传递,提升双尺度模型的协同优化效率。
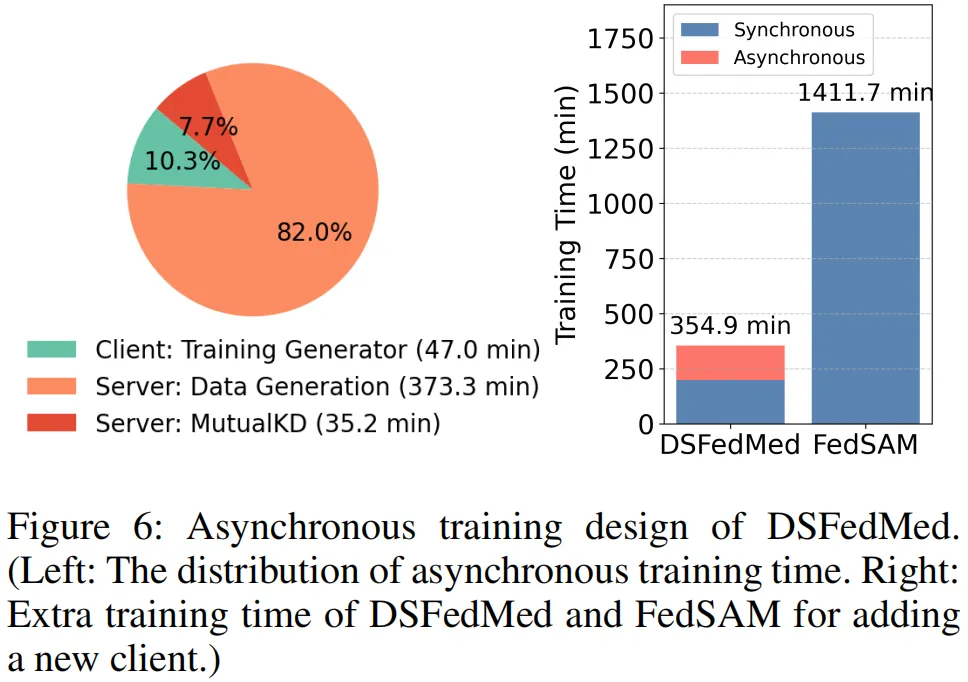
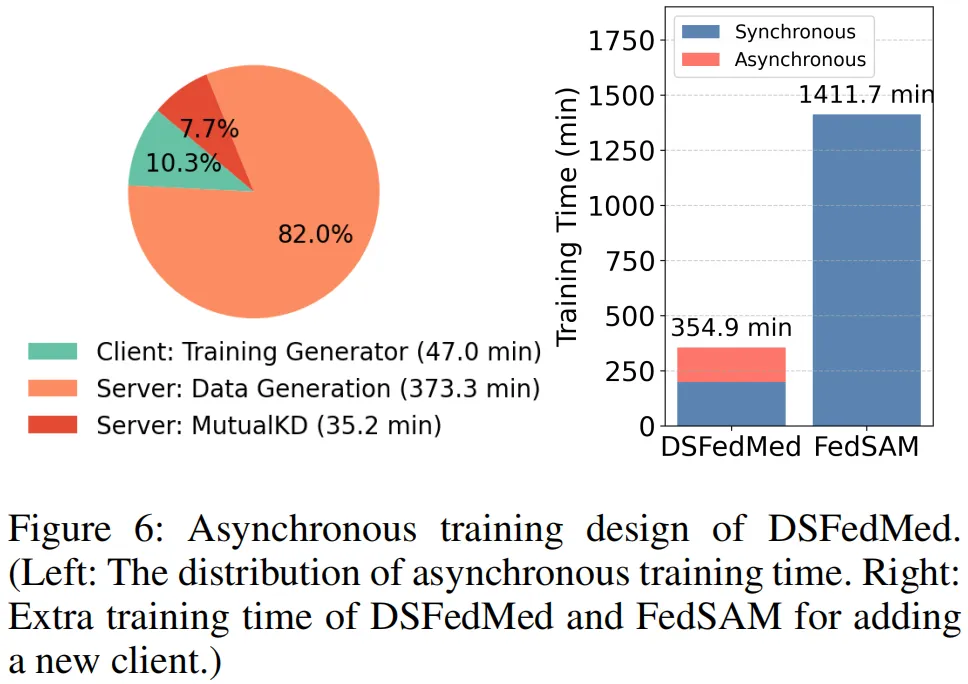
图 6 由左右两图组成,聚焦 DSFedMed 的异步训练设计,直观展现训练时间分布与扩展性优势。左图是异步训练时间分配图,清晰呈现各环节耗时:服务器端数据生成耗时最长(373.3min),其次是客户端生成器训练(47.0min),服务器端互蒸馏耗时最短(35.2min),且多数计算在服务器完成,客户端无需持续在线。右图对比了 DSFedMed 与 FedSAM 新增客户端的额外训练时间,DSFedMed 仅需额外 10.3% 的训练时间,而 FedSAM 需增加 82.0%,凸显前者极强的扩展性。该图印证了异步设计的实用性:既降低客户端资源占用,又支持新客户端快速接入,无需全量重训,为资源受限、多中心协作的医疗联邦场景提供了高效可扩展的训练方案。
实验
5.1实验设置
数据集:5 个 Non-IID 医疗分割数据集(表 2),覆盖眼底、前列腺、细胞核、皮肤 lesion、肝脏等模态,模拟跨中心 / 跨模态联邦场景。
对比基线(表 1):
集中式模型:SAM;
联邦基础模型:FedSAM、FedMSA;
联邦轻量级模型:FedU-Net、FednnU-Net、FedTinySAM。
评价指标:Dice 系数(核心精度指标)、IoU、通信开销(100 轮累计)、推理时间(单图)、训练时间。
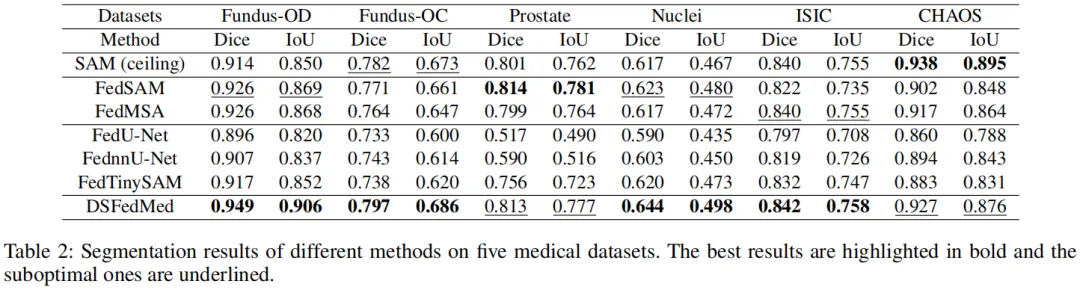
5.2核心实验结果
分割精度(表 2、图 5):
DSFedMed平均 Dice 达 0.829,较 FedSAM(0.810)提升 2%,较 FedTinySAM(0.791)提升 3.8%,甚至超越集中式 SAM(0.815)1.4%,验证了双尺度协同的优势。
可视化结果(图 5)显示,DSFedMed 分割边界更精准,对细结构捕捉更优。
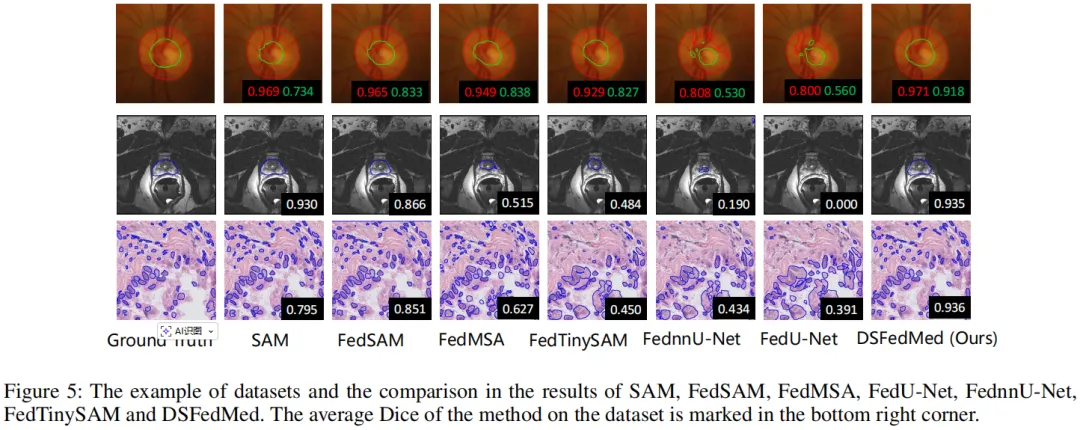
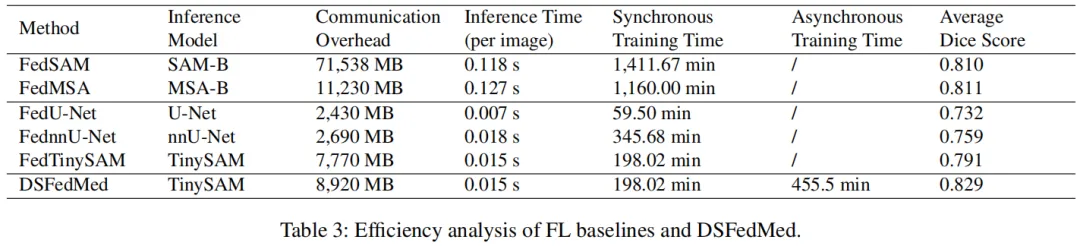
效率分析(表 3、图 1、图 6):
通信开销:较 FedSAM 降低 88%(8920MB vs 71538MB);
推理时间:保持与 FedTinySAM 一致的低延迟(0.015s),远快于 FedSAM(0.118s);
异步训练:服务器端主要耗时为数据生成(373.3min)与互蒸馏(35.2min),客户端仅需 47.0min 训练生成器,新客户端额外训练时间仅 10.3%(图 6 右)。
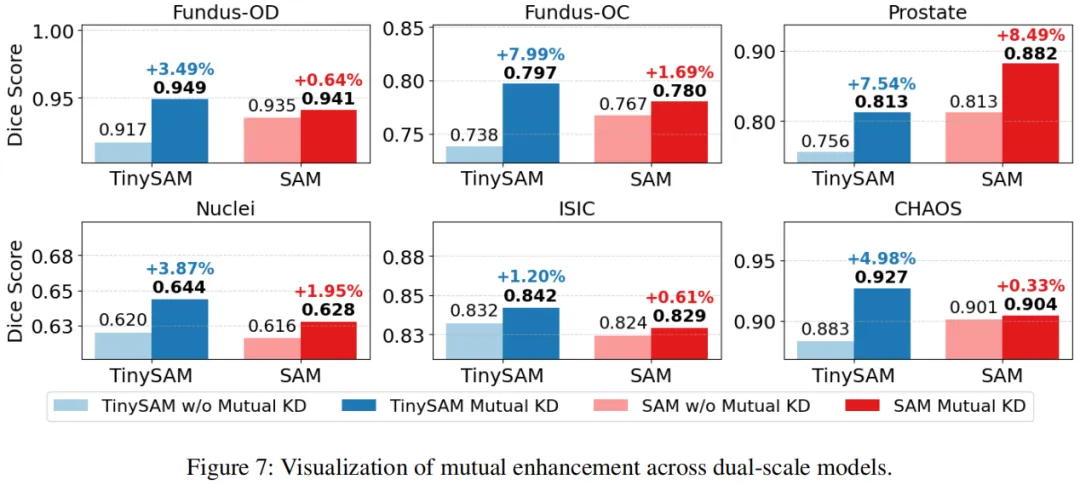
双模型 mutual 增强(图 7):
互蒸馏后,TinySAM 在 Prostate 数据集 Dice 提升 5.7%,Fundus-OC 提升 5.9%;SAM 在 Fundus-OD 提升 0.64%,Prostate 提升 1.69%,证明双向知识传递有效。
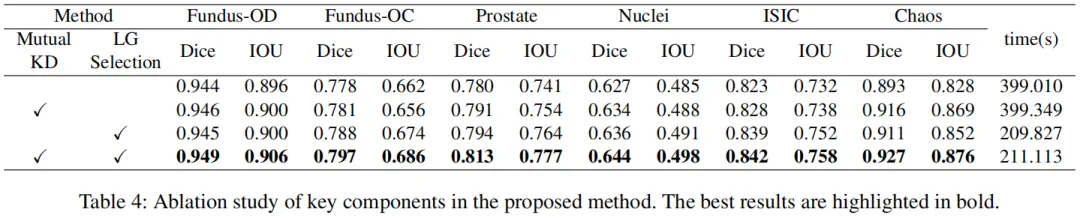
5.3消融实验与扩展性验证
消融实验(表4):
互蒸馏(Mutual KD):单独使用可提升各数据集 Dice,验证双向蒸馏优于单向;
可学习性选择(LG Selection):单独使用可提升精度且训练时间减
半(399min→209min);
两者结合:实现最高精度(如 Fundus-OD Dice 0.949),且训练效率保持最优。
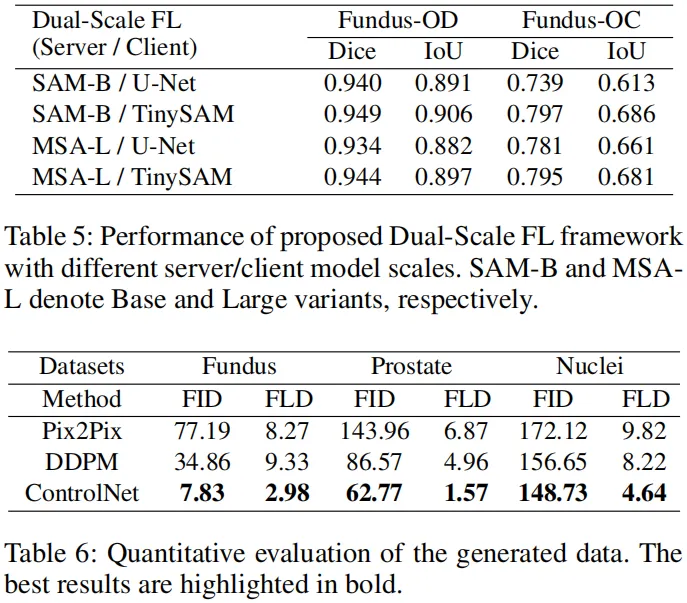
不同模型尺度适配性(表 5):
服务器端 SAM-B + 客户端 TinySAM 组合性能最优(Fundus-OD Dice 0.949),证明框架对不同基础模型(SAM-B/MSA-L)与轻量级模型(U-Net/TinySAM)均兼容。
生成数据质量(表 6):
基于 ControlNet 的生成数据 FID 最小(Fundus 数据集 7.83)、FLD 最小(2.98),优于 Pix2Pix(FID 77.19)与 DDPM(FID 34.86),验证合成数据的高保真与适配性。
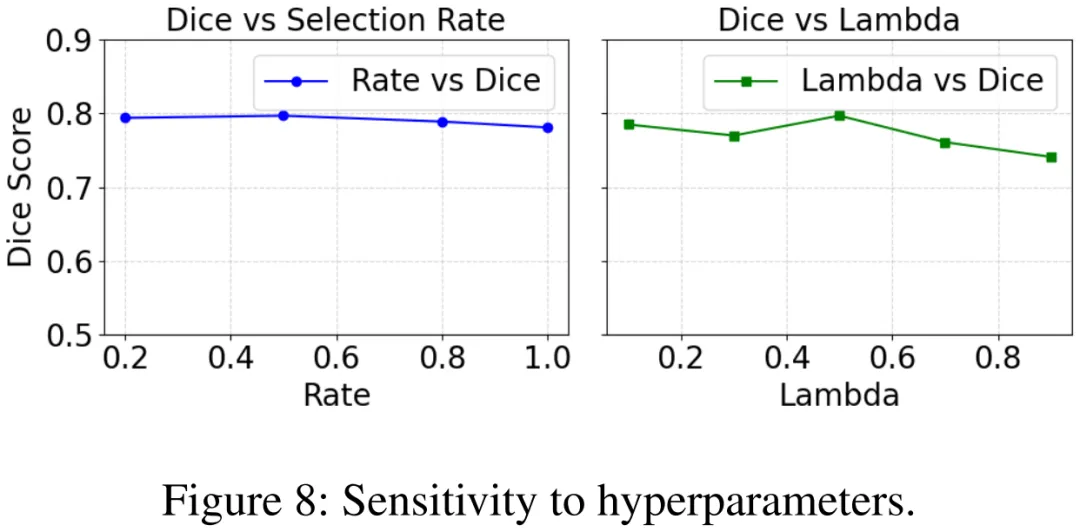
超参数敏感性(图 8):
选择率 0.2-0.8 时 Dice 稳定最优,λ=0.5 时性能峰值,框架对超参数鲁棒。
总结
针对医疗联邦图像分割中基础模型部署难、轻量级模型精度低的核心问题,提出 DSFedMed 双尺度联邦学习框架。其核心创新包括三方面:一是构建服务器 - 客户端双尺度架构,融合基础模型泛化能力与轻量级模型部署效率;二是基于 ControlNet 设计模态自适应生成器,生成高保真合成数据支撑无真实数据知识传递;三是提出可学习性引导的互蒸馏机制,通过 GT 损失与 KL 散度筛选样本,实现双模型双向增强。在5个Non-IID医疗数据集的实验中,DSFedMed 平均 Dice 系数达 0.829,较联邦基础模型提升 2%,通信开销降低 88%,推理时间仅0.015s。该框架有效解决了医疗联邦场景的资源约束与隐私保护难题,为基础模型在临床的规模化应用提供了创新思路与技术支撑。
--- END ---
编辑|阿超
*本文为论文学习收获分享,受限于知识能力,本文对原文的理解可能存在偏差,最终内容以原论文为准。*本文信息旨在传播和学术交流,若您认为文章内容或图片涉及侵权,请公众号私信或菜单栏点击【联系小编】与我们联系,我们会第一时间进行处理。
点击上方“AI启智汇”,关注我们
持续获取分享
ICCV2025|北航等提出FICGen:视觉-频率增强注意力+实例一致性图+自适应空频聚合,提升退化场景图像生成等任务

