中国学者提出CAML框架,破解医疗AI“可解释性鸿沟”难题
随着人工智能在医疗领域的广泛应用,AI模型的“黑箱”问题日益成为临床部署的核心障碍。尽管近年来可解释性AI技术不断发展,但当前方法仍存在“可解释性鸿沟”——全局解释方法难以提炼直观的通用规则,局部解释方法则无法提供整体图景,导致解释结果模糊、不稳定甚至具有误导性,引发医学界对AI决策风险的严重担忧。全球监管机构如美国FDA已明确要求医疗AI设备需提供人类可理解的决策逻辑,如何在保持高精度的同时实现真正可用的解释,成为领域内亟待突破的瓶颈。
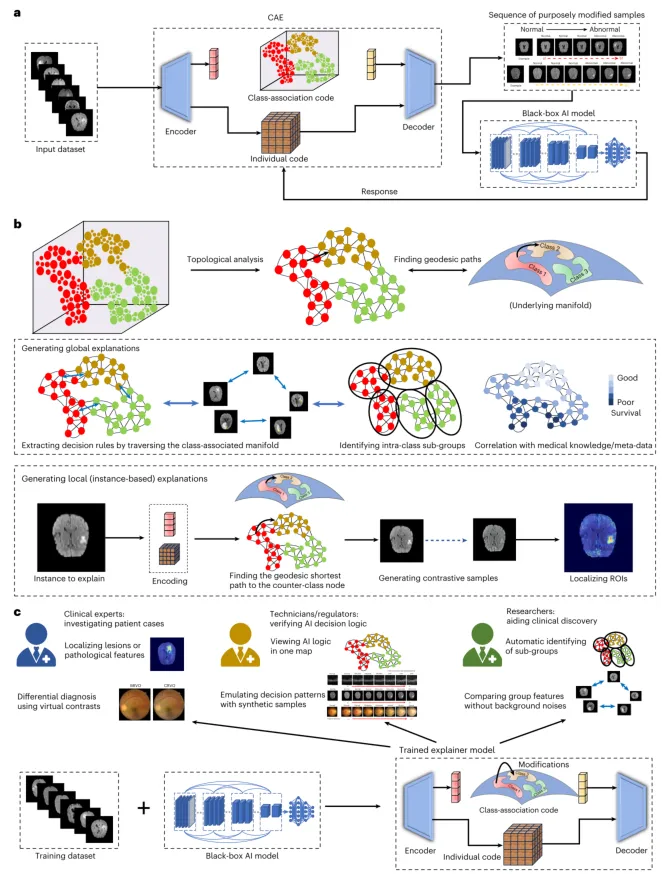
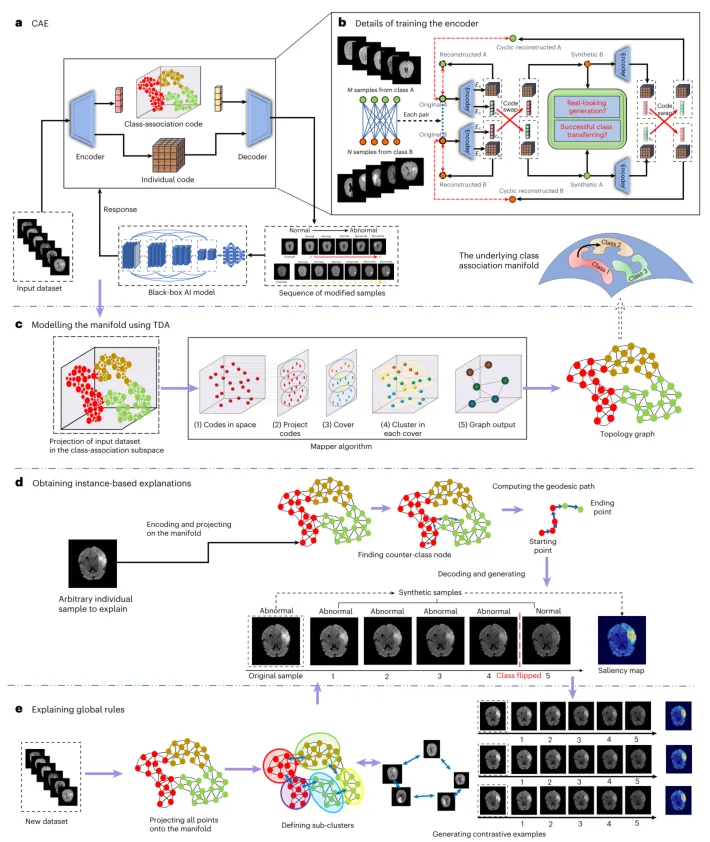
针对这一挑战,中国科学院深圳先进技术研究院(以下简称“深圳先进院”)蔡云鹏研究团队提出了一种名为“类别关联流形学习”的全新可解释AI框架(图1)。该框架通过生成式AI技术,将黑箱模型的决策逻辑压缩至低维空间,并借助拓扑分析生成可遍历的决策规则图谱,同时支持基于反事实生成的个体样本解释。该框架不仅在全球解释和局部解释的精度上均超越现有技术,还能从AI模型中挖掘出符合医学知识但训练时未明确标注的潜在规律,为AI辅助临床规则发现和医学知识挖掘提供了全新路径。相关内容以“Bridging the interpretability gap for medical artificial intelligence models using class-association manifold learning”发表在Nature Biomedical Engineering。
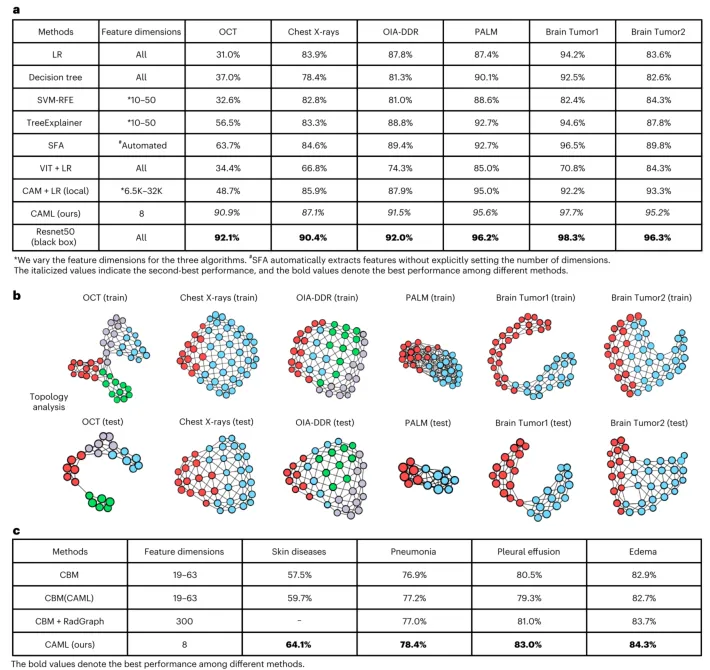
研究团队首先提出了类别关联嵌入算法(图1A),该算法能够将每个样本的类别相关特征与个体背景特征解耦,从而学习到一个低维的类别关联流形。在六个医学影像基准数据集上,仅需8维特征,该流形即可保留原始黑箱模型近95%以上的判别精度,显著优于逻辑回归、决策树等传统白盒模型以及TreeExplainer、Shapley特征增强等全局解释算法(图2A)。例如在OCT数据集中,CAML的分类准确率达到90.9%,而ResNet50黑箱模型为92.1%,两者的性能差距极小。图2B展示了将各数据集投影到所提出的低维流形后的t-SNE可视化结果,正常与病理类别之间呈现清晰分离,训练集与测试集分布高度相似,这解释了类别关联编码空间优异分类性能的原因。进一步在Derm7pt皮肤疾病和MIMIC-CXR胸部X光数据集上与概念瓶颈模型对比,CAML同样展现出更优的诊断性能(图2C),证明了其在有效利用临床相关特征方面的优势。
图1 | CAML框架概述。 a,学习低维全局决策规则空间的CAE算法。b,探索类别关联流形以获取模型决策规则并指导生成全局或局部解释的拓扑分析算法。c,采用解释模型执行各种诊断或临床研究任务。BRVO,视网膜分支静脉阻塞;CRVO,视网膜中央静脉阻塞。
图2 | CAE成功提取全局决策规则模式。 a,在基准数据集上,使用完整输入的目标黑箱模型、类别关联子空间上的分类器以及提取特征或完整输入上的全局可解释或白盒模型,对测试数据的分类性能比较。b,基准数据集类别关联流形的拓扑分析。红点代表正常类别,其他颜色代表异常类别。对于OCT数据集,紫色、蓝色和绿色分别代表玻璃膜疣、脉络膜新生血管和糖尿病性黄斑水肿亚类;对于OIA-DDR数据集,蓝色、绿色和紫色分别代表轻度、中度和重度。背景中描绘了数据集的t-SNE投影。c,在Derm7pt的五类皮肤疾病任务和MIMIC-CXR的三个分类任务上,基于概念的解释方法与CAML的分类性能对比。由于RadGraph不适用于Derm7pt数据集,因此没有相应的实验结果,相关列以破折号(-)标记。
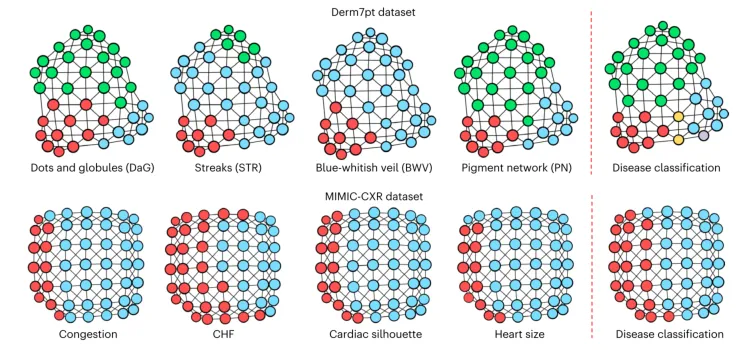
在获得类别关联流形后,研究团队进一步引入了拓扑数据分析方法(图1B)。与传统的主成分分析或t-SNE降维不同,拓扑分析能够保留流形中的测地线关系,构建出包含子簇及其相互连接的拓扑图。图3A(1)展示了OCT数据流形的t-SNE投影,并标出了三条从正常到病理样本的线性路径;图3A(2)展示了这些路径对应的原始图像;图3A(3)则展示了使用相应类别关联码生成的合成样本,病变特征在路径上持续演变且形状相似,验证了流形在聚集相似类别样式方面的局部保持特性。图3B左侧展示了OCT、Brain Tumor2和OIA-DDR数据集上类别关联流形的拓扑图表示,右侧展示了沿拓扑图中选定路径使用类别关联码生成的一系列样本。在OCT数据中,正常类别首先连接到玻璃膜疣,再连接到脉络膜新生血管,符合玻璃膜疣可发展为脉络膜新生血管的医学规律;而糖尿病性黄斑水肿则向另一方向演化,提示其不同的致病机制。在OIA-DDR数据中,轻度、中度、重度糖尿病视网膜病变样本沿拓扑图有序排列,沿路径生成的合成样本病变特征持续演变且位置一致,生动展示了疾病进展规律。图3C左侧展示了包含29个类别的视网膜眼底多疾病数据集的拓扑图表示,右侧展示了沿选定路径生成的样本序列。拓扑分析揭示的类间关系如视网膜分支静脉阻塞与视网膜中央静脉阻塞的邻近、视网膜中央静脉阻塞与视盘水肿的毗邻、糖尿病视网膜病变与视网膜炎的相近、视网膜炎与脉络膜视网膜炎的相邻等,均与临床知识高度吻合,展现了该方法在病因学分析和知识挖掘中的强大能力。图4展示了Derm7pt和MIMIC-CXR数据集中类别关联流形上多个概念注释的分布,疾病相关的概念注释与疾病标签之间存在相关性,尽管这些概念在训练中并未使用,表明CAML能够在无概念监督的情况下学习概念知识,超越了需要在标记概念上训练的现有概念瓶颈方法。
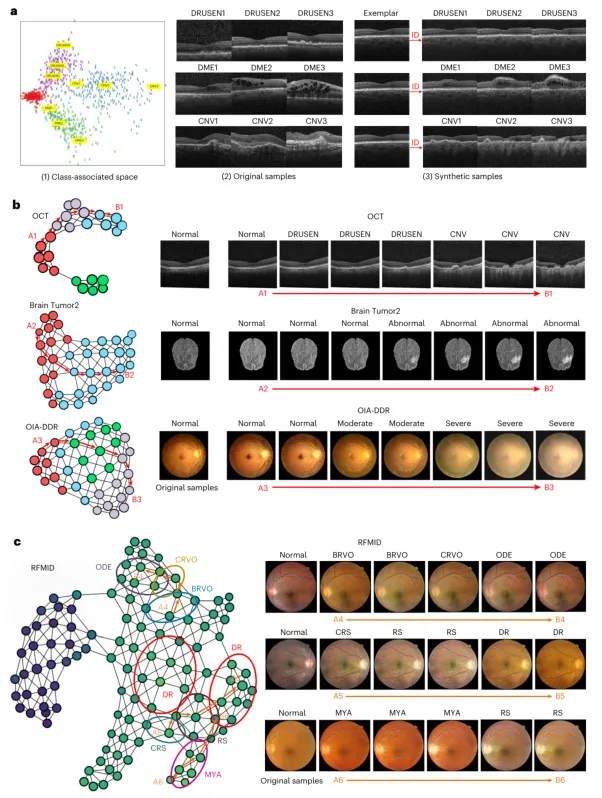
图3 | 类别关联流形上展示的全局决策规则与潜在知识。 a,(1)OCT数据集类别关联流形的t-SNE可视化。(2)沿类别关联流形中三条线性路径(如(1)中黄色框所示)采样的原始图像。(3)使用来自(2)的相应类别关联码生成的合成样本,其病理特征得以复现。b,左侧展示了OCT、Brain Tumor2和OIA-DDR数据集上类别关联流形的拓扑图表示,显示了隐藏的亚类结构。同时,展示了沿拓扑图中选定路径使用类别关联码获得的一系列生成样本。病理特征在各样本间一致演变,这些演变趋势直观地解释了关于图像特征与疾病分级或亚型之间联系的临床规则。c,左侧展示了RFMID数据集(共29类)上类别关联流形的拓扑图表示。不同疾病的样本主要分布在不同颜色圈出的区域中(由于类别数量大,此处仅展示部分类别)。同时,右侧展示了沿拓扑图中选定路径生成的一系列样本。
图4 | 从Derm7pt数据集和MIMIC-CXR数据集学习的类别关联流形(左)中多个概念注释的分布,与疾病分类标签(右)的对比。 在MIMIC-CXR数据集中,蓝色节点代表阴性类别,红色节点代表阳性类别。在Derm7pt数据集中,对于概念DaG(退变与颗粒)和STR(条纹),蓝色节点代表缺失类别,红色节点代表不规则类别,绿色节点代表规则类别。对于概念BwV(蓝白幕),蓝色节点代表缺失类别,红色节点代表存在类别。对于疾病标签BCC(基底细胞癌)、MEL(黑色素瘤)、NEV(痣)、SK(脂溢性角化病)和MISC(其他),不同颜色代表不同的疾病类别。
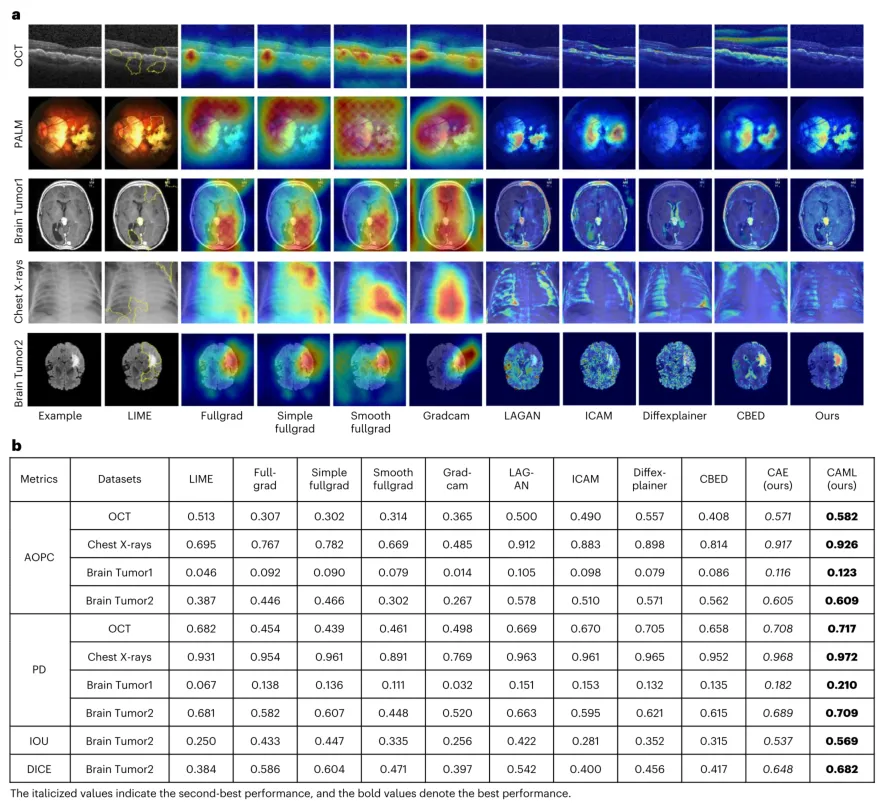
除了全局知识发现,CAML还能生成更精准的个体显著性图谱(图1C)。图5A展示了在OCT、Brain Tumor1、Brain Tumor2、Chest X-rays和PALM数据集上,CAML与其他九种主流可解释性方法生成的显著性图谱对比,CAML生成的感兴趣区域更加准确、精细且轮廓清晰。在OCT、Brain Tumor1、Brain Tumor2和Chest X-rays数据集上的量化评估表明,CAML在峰值退化、扰动曲线下面积等指标上均优于LIME、Fullgrad、Grad-CAM、ICAM等现有方法(图5B)。尤其在Brain Tumor2数据集上,CAML与人工标注的交并比和Dice系数分别达到0.569和0.682,远优于其他方法,意味着该方法可在无像素级标注的情况下实现病灶检测与定位。
图5 | 采用CAE解释单个图像的结果及与现有方法的比较。 a,使用不同方法(包括LIME、Fullgrad、Simple fullgrad、Smooth fullgrad、Grad-CAM、LAGAN、ICAM、Difflexplainer和CBED)在OCT、Brain Tumor1、Brain Tumor2、Chest X-rays和PALM数据集上生成的显著性图谱比较结果。b,使用归因指标(AOPC和PD)和定位精度指标(IOU和DICE),在基准数据集上对不同xAI方法获得的显著性图谱精度进行定量评估。
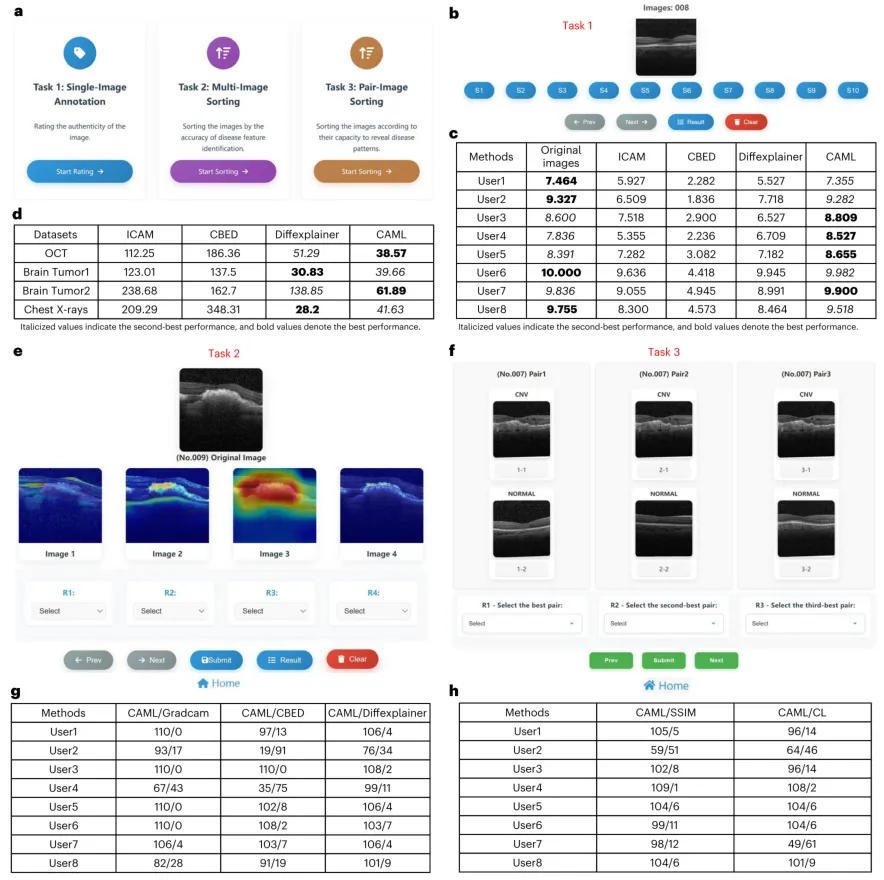
为验证方法的临床可靠性,研究团队邀请八名眼科临床医生在OCT数据集上进行了三组盲法评估。评估网站界面如图6A所示。在第一项评估中(图6B),医生对CAML生成的图像真实性评分最高,接近原始图像,优于ICAM、CBED、Diffexplainer三种反事实生成方法(图6C)。图6D展示了四种反事实生成方法在四个数据集上的FID值,CAML同样取得了具有竞争力的性能。在第二项评估中(图6E),CAML生成的显著性图谱在准确识别疾病病理特征方面获得医生最高排名(图6G)。在第三项评估中(图6F),医生一致认为CAML生成的对比样本对最能清晰展示两类疾病之间的鉴别诊断特征,优于按结构相似性指数匹配的真实图像和对标节点中心真实图像(图6H)。这些结果表明,CAML生成的反事实对比样本能够有效去除背景差异,帮助临床医生更准确地识别病理特征,从而增强了临床对AI决策的信任。
图6 | OCT数据集上的可靠性评估。 a,评估网站界面,包含三项任务。b,保真度评分界面(S1至S10:从最低到最高)。c,八名临床医生对原始图像和不同方法生成图像给出的保真度评分。d,四种反事实生成方法在四个数据集上的FID值。e,显著性图谱排序界面(R1至R4:从最佳到最差)。f,鉴别诊断模式排序界面(R1至R3:从最佳到最差)。g,显著性图谱评估的排序结果。图中展示了临床医生将对应方法排名优于其他方法的实例数量。h,鉴别诊断模式排序结果。图中展示了临床医生将对应方法排名优于其他方法的实例数量。
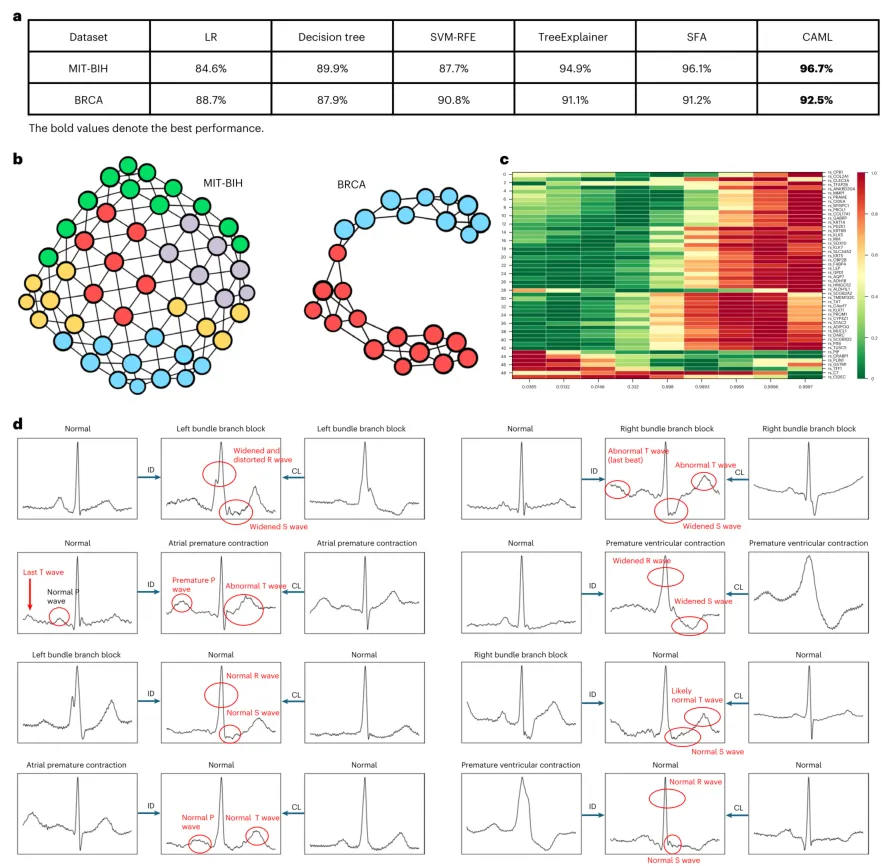
研究团队还通过系列实验验证了CAML的鲁棒性和扩展性。在不平衡数据集MIMIC-CXR和CheXpert上,CAML保持了高质量的分类和反事实生成能力。在跨数据集NIH-CXR到CheXpert的迁移实验中(扩展数据图1A),CAML的精度下降仅为3.6%,优于原始黑箱模型的9.9%下降;扩展数据图1B展示了在CheXpert测试集上获得的类别关联流形,无论是使用NIH-CXR数据集训练还是使用CheXpert训练集训练,所获得的流形结构保持高度一致。在对抗捷径学习方面,扩展数据图2展示了CAML在处理含有伪影的NIH-CXR和CheXpert样本时的表现,CAML成功避免了在反事实生成过程中迁移或错误擦除这些伪影,表明给定正确的分类模型,CAML能够将临床相关特征与虚假相关性解耦。扩展数据图3则展示了当分类器陷入捷径学习时CAML的检测能力:在病理性近视样本经过亮度增强的PALM数据集上训练后,CAML揭示了一条仅通过改变亮度即可导致误分类的路径,有效暴露了模型的脆弱性。在心电图和基因表达数据上的实验同样验证了该方法的普适性(图7A)。图7B展示了CAML在MIT-BIH ECG和BRCA基因数据上获得的类别关联流形。图7C展示了基因数据的跨类别生成示例,沿路径生成的一系列样本中关键基因表达变化的热图清晰呈现。图7D展示了ECG数据集的跨类别生成示例,CAML生成的左束支传导阻滞、右束支传导阻滞、房性期前收缩和室性期前收缩等心电特征与医学知识高度吻合。
图7 | 非图像数据集上的实验结果。 a,不同xAI方法在MIT-BIH ECG数据集和BRCA基因数据集上的分类结果。b,CAML方法在MIT-BIH ECG和BRCA基因数据上获得的类别关联流形。在ECG流形中,红色代表正常类别,蓝色代表左束支传导阻滞,绿色代表右束支传导阻滞,紫色代表房性期前收缩,棕色代表室性期前收缩。在基因数据流形中,红色代表浸润性导管癌类别,蓝色代表浸润性小叶癌类别。c,基因数据的跨类别生成示例,展示了沿从浸润性导管癌样本向浸润性小叶癌样本路径获取CL码生成的一系列样本的关键基因表达变化热图,底部显示了分类器预测的目标浸润性小叶癌类别概率。d,ECG数据集的跨类别生成示例,样本上方显示了分类器预测结果。
图8展示了CAML框架的完整方法流程图,包括类别关联嵌入算法(图8A)、使用构建块一致性特征提取算法的训练过程(图8B)、使用Mapper算法建模和可视化类别关联流形的拓扑数据分析步骤(图8C)、通过沿引导路径生成对比样本创建显著性图谱以获得基于实例的解释(图8D),以及通过子分组和生成对比样本来解释全局规则(图8E)。研究团队通过消融实验验证了嵌入维度的选择对大多数数据集而言在8至128维之间分类精度变化平稳,表明CAML在超参数选择方面具有高度鲁棒性。计算效率对比显示,CAML在模型训练和生成实例解释所需的计算时间均优于其他方法。
图8 | CAML框架的方法流程图。 a,CAE。b,使用构建块一致性特征提取算法的CAE框架训练过程。c,使用Mapper算法建模和可视化类别关联流形的TDA步骤。d,通过沿引导路径生成对比样本并创建显著性图谱,获得基于实例的解释。e,通过子分组和生成对比样本来解释全局规则。
尽管CAML在医学AI可解释性方面取得了重要突破,团队指出仍存在若干局限。当前的可解释特征虽具有临床合理性,但尚未系统性地转化为直接与临床知识对齐的语言描述,未来结合大语言模型有望将图像特征转化为概念化解释。此外,生成式解释仍可能引入伪影或偏差,人类专家的审核依然不可或缺。目前方法主要针对分类器模型,对生成式AI模型的解释将是未来的研究方向。总体而言,该研究证明了黑箱医疗AI的全局决策逻辑可以通过解耦共性规则与个体背景,被高效压缩至低维空间。CAML框架通过流形学习和生成式AI,为建立可信、可解释的医疗AI模型提供了有力工具,有望推动AI技术在临床研究和实践中的安全部署。

「BioMed科技」关注生物医药×化学材料交叉前沿研究进展!交流、合作,请添加杨主编微信!

来源:BioMed科技声明:仅代表作者个人观点,作者水平有限,如有不科学之处,请在下方留言指正!


 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
