本文来自arxiv2026年3月份(其实也就是前两天)的最新热乎文章,想要实时追踪最新的具身导航arxiv成果和顶会成果,敬请关注"具身智能导航"!
❝- 论文标题: AerialVLA: A Vision-Language-Action Model for UAV Navigation via Minimalist End-to-End Control
- 作者: Peng Xu, Zhengnan Deng, Jiayan Deng, Zonghua Gu, Shaohua Wan
- 单位: 电子科技大学深圳高等研究院, 美国霍夫斯特拉大学计算机科学系
- 论文链接: https://arxiv.org/abs/2603.14363
- 代码链接: https://github.com/XuPeng23/AerialVLA
一段话总结
本文提出了AerialVLA,一种面向无人机视觉语言导航(UAV-VLN)的极简端到端视觉-语言-动作框架。该框架将原始视觉观测和模糊语言指令直接映射为连续物理控制信号,彻底摆脱了现有方法对密集路径指导和外部目标检测器的依赖。通过精简的双视图感知、基于机载传感器的模糊方向提示以及统一的三自由度控制空间,AerialVLA在TravelUAV基准测试中取得了已知环境的最优性能,并在未知场景中实现了约三倍于最强基线的成功率,证明了极简自主范式相较于复杂模块化系统具有更强的泛化能力。
1 研究背景:无人机导航的"双拐杖"困境
视觉语言导航(VLN)旨在让智能体根据自然语言描述,在环境中自主导航至目标位置。这一方向在地面机器人中已取得显著进展,但将其扩展到无人机(UAV)面临独特挑战:无人机需要在完整的六自由度(6-DoF)状态空间中飞行,同时从不断变化的自我中心视角解读视觉线索,并在重力和惯性约束下进行连续控制。
然而,现有的无人机VLN方法普遍依赖论文中所称的"双拐杖"(double crutches),严重制约了其在真实场景中的自主性。第一根拐杖是密集的先知指导(oracle guidance):现有方法在输入中注入基于预录制最优轨迹的逐步方向提示(如"向右转"),这本质上把导航智能体降格为被动的指令执行者,绕过了主动空间推理这一核心挑战。第二根拐杖是外部目标检测器:由于缺乏细粒度的视觉定位能力,现有方法需要依赖Grounding DINO等外部检测器来触发降落阶段,导致感知-控制回路断裂——策略学会了"怎么飞",却要依赖外部黑盒来决定"何时停"。
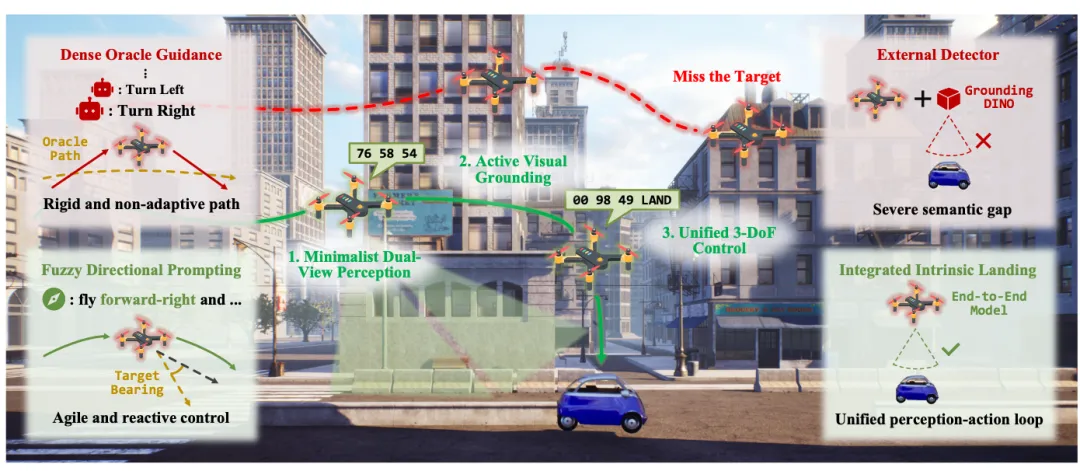 对应原文Fig.1:无人机导航范式对比图
对应原文Fig.1:无人机导航范式对比图AerialVLA正是为了解决这一"双拐杖"问题而提出的。它建立了统一的感知-动作回路,用模糊的机载方向提示替代精确先知,用内在的着陆策略替代外部检测器,使无人机真正实现自主导航。
2 主要贡献
本文的核心贡献可以概括为以下三点:
- 极简双视图感知:仅融合前视和下视两个视图,抛弃了多相机冗余,在保留前向导航和精确目标定位所需关键线索的同时,降低了计算开销并为未来的仿真到真实迁移奠定基础。
- 模糊方向提示:完全消除对逐步先知指导的依赖,仅利用机载IMU传感器估计的粗粒度方向信息构建提示,迫使智能体学习主动的视觉空间推理能力。
- 基于数值标记化的高自由度控制:将连续的三自由度动作空间与内在降落信号统一编码为数值标记,直接复用大语言模型预训练的数值推理能力,无需外部检测器即可实现巡航与精确着陆的一体化控制。
3 方法:极简设计的端到端架构
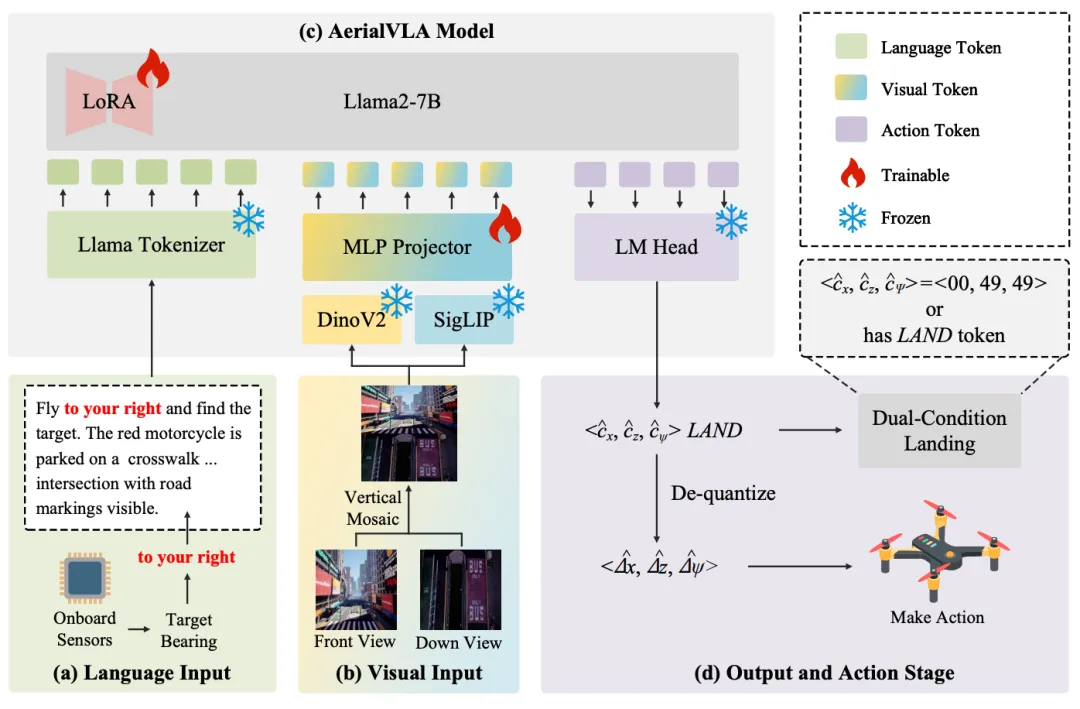 对应原文Fig.2:AerialVLA整体架构图
对应原文Fig.2:AerialVLA整体架构图AerialVLA的整体架构如图2所示,基于OpenVLA-7B骨干网络构建,核心包括混合视觉编码器和Llama 2语言模型。框架接收多模态输入(语言提示和双视图图像),通过自回归方式预测数值控制标记,最终解码为连续的物理控制命令。以下逐一介绍各个关键模块。
3.1 极简双视图感知——只看最关键的视角
现有UAV-VLN基准通常模拟五个相机视角,但高维输入会大幅增加计算负担和推理延迟。更重要的是,冗余视角对前向飞行任务的实际贡献有限。AerialVLA只保留前视图和下视图:前视图提供障碍物规避和目标识别的关键线索,下视图则对精确地面对齐和降落至关重要。
具体做法是将前视图像 和下视图像 进行垂直拼接,形成复合观测图 ,再缩放到224×224分辨率。该复合图像由SigLIP和DINOv2两个视觉编码器联合处理:SigLIP提供语言对齐的语义特征,DINOv2捕捉鲁棒的细粒度空间表征。
这一设计有一个巧妙之处:AirSim中默认的90°视场角使前视和下视图像在水平边界处自然衔接,具有物理和语义连续性。而224×224的输入尺寸恰好使拼接缝与ViT编码器的14×14 patch网格对齐,避免了patch内部的图像内容混乱,使自注意力机制能够干净地解析跨视图的空间关系。
3.2 模糊方向提示——从被动执行到主动推理
现有方法(如TravelUAV)在输入提示中注入从预录制最优轨迹导出的密集逐步指令(如"向左转""向右转"),这让智能体变成了"复读机"。AerialVLA彻底移除了这种依赖,仅使用来自机载传感器(IMU/GPS)的模糊方向提示。
具体而言,系统定义了一个映射函数 ,将目标相对方位角 离散化为粗粒度的语义类别。例如,当 时提示为"straight ahead"(正前方), 时为"forward-right/left"(前方偏右/左), 时为"to your right/left"(右/左方), 时为"to your right/left rear"(右/左后方)。
这种设计的核心思想是:刻意引入空间模糊性。相较于精确的逐步路径指令,粗粒度的方向提示只告诉智能体目标大致在哪个方向,而非具体怎么飞。这迫使模型必须依赖主动的视觉定位能力来完成导航任务,同时也更贴合真实世界中传感器定位的不确定性。
完整的提示由四部分组成:(1) 视觉占位符<image>,(2) 模糊方向提示(如"to your right"),(3) 目标的详细自然语言描述,(4) 对应的数值控制动作。AerialVLA采用完全反应式策略,严格基于当前帧观测和即时方向提示做出决策,不维护复杂的时空记忆缓冲区,从而大幅降低推理延迟并避免过时状态的累积误差。
3.3 几何一致性过滤——消除训练数据中的歧义
在使用模糊提示训练时,专家演示数据中存在一类歧义:当目标在侧方()但飞行员因反应延迟仍在直飞()时,方向提示与动作标签之间存在因果矛盾。
为解决这一问题,AerialVLA提出了基于侧向深度图的几何一致性过滤策略:对于上述歧义帧,检查侧向深度图 。如果侧方空间畅通(),则判定为飞行员延迟反应造成的噪声标签,予以丢弃。但如果侧方存在障碍物(),则保留该直飞标签,因为它代表合理的避障动作。这一过滤仅移除了约4%的训练帧,但有效消除了矛盾性监督信号。
3.4 数值标记化的高自由度控制——一个策略搞定飞行和降落
动作空间设计。 AerialVLA定义了连续的三自由度动作空间 ,分别控制前进位移、垂直位移和偏航角变化,将低级稳定性控制(如横滚/俯仰)交给飞控器处理。这一设计与商用无人机API(如DJI SDK、PX4)暴露的高层运动原语一致,便于真实部署。
内在降落策略。 与现有方法依赖外部检测器触发降落不同,AerialVLA学习了内在的停止策略。在训练阶段,终端帧被标注为零位移向量 和文本标记"LAND"。推理时通过双条件检查执行降落:要么模型生成了"LAND"标记,要么预测的空间偏移接近零。这将导航和降落统一在单一行为克隆目标中。
标准数值标记化。 此前的VLA方法(如RT-2)引入特殊的动作标记(如<act_0>到<act_255>),但在数据稀缺的无人机领域,从头训练这些嵌入会带来严重的冷启动问题。AerialVLA将连续动作维度离散化为 个bin,直接映射到LLM词表中已有的数字标记(00-98)。这巧妙地复用了预训练模型对数值大小和顺序关系的理解,使模型能更快收敛并产生更平滑的控制轨迹。
在每个时间步,模型自回归地预测三个整数标记:
其中 ,随后被确定性地反量化为连续物理命令:前进位移 米、垂直位移 米、偏航变化 弧度。为保证飞行平稳,系统以恒定巡航速度(1.0 m/s)将空间偏移转换为速度-时长命令,避免突兀的运动学跳变和相机运动模糊。
3.5 训练目标
训练采用标准的行为克隆(Behavior Cloning)框架。给定专家演示数据集 ,优化目标为最小化专家动作标记的负对数似然:
$$\mathcal{L} = - \mathbb{E}_{(I_t, P, a^*_t) \sim \mathcal{D}} \left[ \sum_{k \in \{x, z, \psi\}} \log p(a^*_{t,k} \mid I_t, P, a^*_{t,<k}) \right]="" $$="" 这种逐帧监督与反应式导航策略完美契合。4 实验设置与结果
4.1 数据集与评估指标
实验在TravelUAV基准的UAV-Need-Help任务上进行,该数据集包含约12k条人类飞行员操控的轨迹。训练集包含7,922条轨迹(420k帧),测试集分为三个子集:Seen(1,418条)、Unseen Object(629条)和Unseen Map(958条),分别测试已知环境、未见目标和未见地图下的性能。
评估指标包括:导航误差(NE,到目标的欧氏距离)、成功率(SR,终点距目标20米以内的比例)、先知成功率(OSR)以及路径长度加权成功率(SPL)。
模型基于OpenVLA-7B骨干,对语言模型应用LoRA适配(r=64, α=128),仅训练约2.98%的参数。视觉编码器冻结,投影器全量微调。在4块RTX 4090上训练5个epoch,耗时约35小时。
4.2 主要实验结果
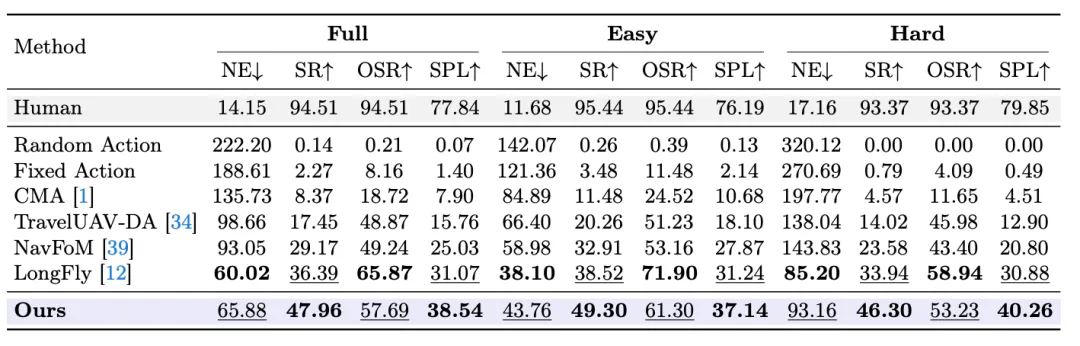 对应原文Table 2:实验结果
对应原文Table 2:实验结果已知环境(Seen)。 AerialVLA取得了47.96%的SR和38.54%的SPL,分别超越最强基线LongFly 11.57%和7.47%。在困难子集上优势更为明显(SR高出12.36%)。值得注意的是,LongFly虽然借助先知指导获得了更高的OSR(65.87%),但其从OSR到SR的转化效率很低,这暴露了其在最终着陆阶段的严重失败——而AerialVLA凭借内在停止机制展现了显著更好的OSR-to-SR转化。
未见目标(Unseen Object)。 AerialVLA以56.60%的SR保持领先。基线方法由于依赖显式目标检测器,在面对训练时未见过的目标类别时识别和停止能力受限。AerialVLA则直接将新颖的视觉概念关联到控制动作,表明其极简框架有效利用了LLM中的开放词汇表征能力。
未见地图(Unseen Map)。 这是泛化能力的最强考验。在全新环境中,LongFly的SR急剧下降到11.27%,而AerialVLA实现了37.58%的SR和28.22%的SPL——约为最强基线的三倍。这说明AerialVLA习得了一种基础性的视觉伺服能力,而非对特定地图的记忆。其严格依赖即时观测的反应式策略在面对剧烈环境变化时展现出了远超基于时空记忆方法的鲁棒性。
4.3 计算效率
在RTX 4090上,AerialVLA所需显存为17GB,总推理延迟为0.38秒,优于TravelUAV的20GB和0.63秒。虽然双视觉VLA模型本身推理需0.35秒(略高于TravelUAV骨干网络的0.26秒),但由于完全省去了辅助模块和Grounding DINO检测器(0.37秒),系统总延迟显著降低。
4.4 消融实验
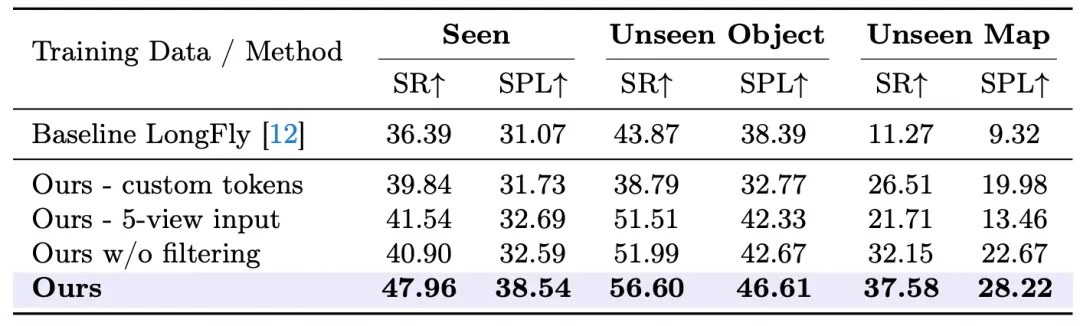 对应原文Table 5:消融实验结果
对应原文Table 5:消融实验结果消融实验验证了各设计组件的有效性:
- 数据过滤的作用:在未过滤的原始数据上训练,未见地图SR从37.58%降至32.15%(下降5.43%),但仍保持接近LongFly三倍的优势,证明性能提升主要来自架构设计而非数据清洗。
- 双视图 vs 五视图:使用五视图输入的变体在未见地图SR上从37.58%骤降至21.71%,验证了冗余视角会导致过拟合于背景杂乱信息,实证支持了极简双视图设计。
- 数值标记化 vs 自定义标记:使用自定义动作标记的变体在所有测试子集上均出现显著下降,验证了从头训练新嵌入的冷启动问题,而复用数值标记能有效利用LLM的预训练数值认知。
4.5 定性分析
论文展示了两种典型导航行为:一是在森林等杂乱环境中的精细操控,智能体先水平对齐目标再精确垂直下降;二是面对干扰物时的主动纠错,智能体接近错误目标后主动悬停检查,识别不匹配后自主爬升继续搜索。这种主动感知回路展现了超越简单轨迹回归的自校正能力。
5 总结
AerialVLA通过极简的端到端设计范式,从根本上重新审视了无人机视觉语言导航中的模块化方法论。它仅依赖机载模糊方向提示进行导航,并将巡航与精确着陆统一到单一自主策略中,完全解耦了对密集先知指导和外部目标检测器的依赖。实验表明,抛弃冗余的空间记忆和复杂辅助模块反而能促进更出色的零样本泛化能力。
局限性方面,作者指出两点:一是反应式策略缺乏显式历史记忆,在高度重复的城市结构中可能面临全局回溯困难;二是行为克隆的固有局限使策略在极端分布外场景中趋于保守(如目标被茂密树冠遮挡时,智能体倾向于安全悬停而非执行复杂多阶段探索)。
未来方向包括:集成轻量化记忆机制以增强全局推理能力,以及探索强化学习微调以实现超越静态专家演示的主动探索行为。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
