我们见过太多让大模型(LLM)指挥机器人做咖啡、叠衣服的研究,看着很酷,但总觉得离真正的“生产力”差点意思。因为工厂车间里的活儿,可比做咖啡复杂太多了:不是一台机器人,而是好几台;不是顺序执行,而是要并行、要避让、要抢资源。让LLM直接调度,就像让一个语言天才去同时指挥20个厨师做满汉全席——他懂菜谱,但完全不懂后厨的流程和资源分配,结果必然是乱作一团。
今天要解读的这篇论文,恰恰解决了这个问题。它没有让LLM“硬刚”调度难题,而是让它回归自己最擅长的事:理解任务、拆解流程、构建模型。然后,把最棘手的调度问题,交给成熟的确定性算法去解决。这套组合拳,在复杂的工业多机器人任务上,成功率直接提升到了68%,而此前最强的方法只有24%。
这不仅是技术上的突破,更是一种思路上的纠偏:在工业场景下,LLM不该是“独裁者”,而应该是“总参谋部”和“金牌教官”。
论文标题:IMR-LLM: Industrial Multi-Robot Task Planning and Program Generation using Large Language Models
核心作者:Xiangyu Su, Juzhan Xu, Oliver van Kaick, Kai Xu, Ruizhen Hu
核心机构:深圳大学、速腾聚创(SpeedBot Robotics)、卡尔顿大学、中国科学院(AI for Industries研究所)
论文链接:https://arxiv.org/pdf/2603.02669
一、核心痛点:让LLM直接调度,等于让诗人去当物流主管
要理解IMR-LLM的创新,得先明白它解决了什么“反人性”的痛点。
想象一下这个场景:一个车间里,有7台机器人,要完成打磨、焊接、倒角、运输、装配等多种任务,共24道工序。这些工序之间有严格的先后顺序,比如“必须先打磨,才能焊接”。同时,机器人和机床都是稀缺资源,不能同时被两个工序占用。
以前的LLM方案(如SMART-LLM, LaMMA-P)是怎么干的?它们试图让LLM“一勺烩”,直接输出一个全局的、谁在什么时候干什么的“执行顺序表”。
这就好比让一个从未学过运筹学的诗人,去规划一个大型物流中心的货车调度。结果可想而知:
可行性低:LLM可能会安排两个工序同时抢占同一台机器人,直接“撞车”。
效率低:即使不撞车,也往往不是最优解。论文实验数据显示,在复杂多机器人任务上,基线方法SMART-LLM的调度效率(SE)仅为0.04(满分为1),基本等于随机乱序。
泛化性差:工业场景的约束是隐性的、复杂的,LLM很难通过几个例子就学会所有规则。
核心批判:LLM的根本问题在于,它本质是一个基于概率的“文字接龙”模型,而非一个能处理严格约束和冲突的“优化求解器”。让它直接输出调度方案,是用错了它的天赋。
二、核心方案:“析取图”+“工序树”,LLM的新角色定位
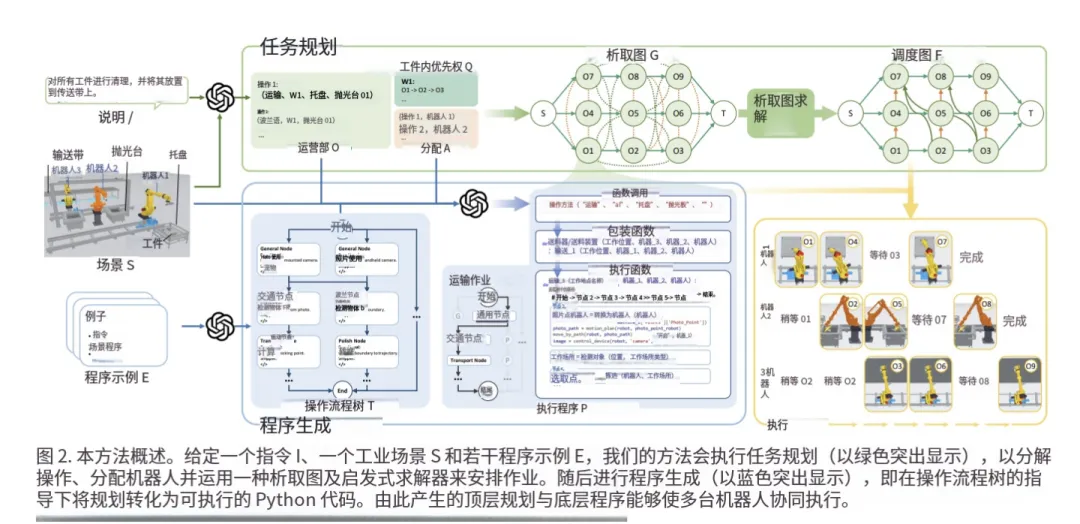
IMR-LLM的解法非常聪明:把任务规划和程序生成拆开,各司其职。
整个框架如图2所示,分为两大核心模块:任务规划(绿色部分)和程序生成(蓝色部分)。
1. 任务规划:LLM负责“搭积木”,算法负责“解谜题”
这里的关键创新,是引入了析取图(Disjunctive Graph)这个经典数据结构。
通俗解释:析取图就像一张“工序关系地图”。其中:
“实线箭头”代表“必须先A后B”的硬性顺序(比如先打磨后焊接)。
“虚线”代表“潜在冲突”,比如两个工序要用同一台机床,或者同一台机器人,它们俩不能同时干,但谁先谁后呢?这是个待定的“选择题”。
工作流程:
第一步(LLM做):给定自然语言指令和场景,LLM不再直接说“谁先谁后”,而是只负责“识别”出所有工序、每个工序该由谁做(分配)、以及工序之间的“实线箭头”关系(同一工件上的顺序)。它就像一个经验丰富的车间主任,把“谁该干什么,谁依赖谁”先梳理清楚。
第二步(算法做):这些信息被转换成一个析取图。然后,论文用一个成熟、高效的启发式算法(FIFO,先进先出)去“解”这个图,也就是为所有“虚线”选择题找到最合理的答案,最终输出一个无冲突、且尽可能并行的可行调度计划。
核心洞察:这一步直接把LLM从“不擅长的调度难题”中解放出来。它只需要处理相对明确的“依赖关系”,而把最复杂的“冲突解决”交给了确定性的、可解释的算法。这不仅提升了效率,还让整个规划过程变得“可解释”,工程师可以轻松回溯每一步决策。
2. 程序生成:“操作过程树”取代“照猫画虎”
有了计划,还得让机器人能执行。传统的“少样本提示”容易让代码过拟合例子,换个环境就不能跑了。
论文发现,工业操作有极强的“流程性”。比如“打磨”,永远是:拍照->识别边界->规划轨迹->移动到起点->打磨->返回。区别只在于“相机是装在机器人手上还是架子上”这类细节。
于是,他们构建了一个“操作过程树”(Operation Process Tree)。
通俗解释:这个树把每个操作(打磨、运输等)都拆解成了标准化的步骤节点。遇到不同场景,就走树上的不同“分支”。比如“拍照”节点下,就有“手眼相机拍照”和“固定支架相机拍照”两个分支。
工作流程:LLM拿到这个树后,它的任务不再是凭空写代码,而是“路径选择”。根据当前场景,为每个操作在树中找到唯一的一条路径,然后把这条路径上所有节点的代码片段“拼接”起来,就得到了一个可完美适配当前环境的执行函数。
这个设计,完美解决了代码可执行性(Exe)和目标达成率(GCR)的问题。
三、重磅实验结论:效率与成功率的碾压式胜利
论文在自建的IMR-Bench基准上,与SMART-LLM、LaMMA-P、LiP-LLM等多种SOTA方法进行了对比。结果可以用“碾压”来形容。
核心结果:如表I所示,IMR-LLM在所有复杂度的任务上,均取得最优。
【论文核心结果表I:不同方法在IMR-Bench上的表现】
| | | |
|---|
| | | 0.00 |
| | | |
| 0.90 | | |
| Ours (GPT-4o) | 0.90 | 0.87 | 0.68 |
| Ours (Qwen3-32B) | 1.00 | 0.87 | 0.68 |
(SR: 成功率,需同时满足最优调度和完全执行)
结论提炼:
在复杂的多机器人任务上,IMR-LLM的成功率(68%)是此前最佳方法(LiP-O,24%)的近3倍。而SMART-LLM更是直接交了白卷(0%),证明了纯LLM调度在复杂工业场景下的彻底失效。
通用性强:论文不仅用了GPT-4o,还用了开源模型Qwen3-32B,同样取得了68%的成功率,甚至在单机器人任务上达到了100%。这说明框架的先进性不依赖于特定模型。
配比的艺术:表II的消融实验揭示了成功的关键。
四、反常识的发现:为什么“记忆模块”能提升“推理能力”?
(此部分灵感来源于论文“程序生成”模块的设计思想,类比“记忆与思考”的经典命题,虽非论文直接实验,但可作为深度解读的升华点)
论文中有一个很反直觉的点:为什么把“操作过程”做成一个固定的“树”去让LLM查,反而比让LLM现场发挥写代码效果更好?这难道不会限制LLM的“创造力”吗?
机制分析:这正是工业场景的残酷要求——不要创造力,要确定性、要可执行。
我们可以用认知心理学中“工作记忆”和“长期记忆”的关系来理解:
LLM的上下文窗口,就是它的“工作记忆”。空间有限,且思考时会占用大量“脑力”。
“操作过程树”,就是一本标准化的“长期记忆”手册。
当LLM需要为每个操作生成代码时:
传统方法:它得从“工作记忆”的几个例子里,硬“推理”出代码结构,这就像考试时不给公式,让你自己推导。结果就是容易出错(低Exe),或者漏步骤(低GCR)。
IMR-LLM方法:它只需要查手册(过程树),找到对应的“公式”(代码片段),然后填上具体的参数(位置、机器人ID等)。这就像开卷考试,省下了推导公式的时间,全部用来专心解题(理解场景、选择路径)。
意外增益:论文提到,这个过程树只需构建一次,就可复用于所有场景。这种“模块化”和“可复用性”,大大降低了LLM生成代码的“认知负载”,使其在长上下文、复杂场景下,依然能保持高水平的执行表现。
五、工程落地:把“字典”放在“抽屉”里
IMR-LLM的另一大优势,是它的工程友好性。
核心优势提炼:它将“调度逻辑”和“执行代码”解耦了。
调度逻辑(析取图+求解器)是“大脑”,负责思考“下一步做什么”。这部分很重,但算法确定,可优化。
执行代码(过程树+代码生成)是“手脚”,负责“怎么做”。这部分很细,但模块化,可复用。
这种解耦带来了巨大的工程优势:
可解释性与可调试性:如果调度错了,你可以去检查析取图,而不是去分析LLM的“黑盒”输出。如果代码执行错了,你只需要修改过程树中对应节点的代码片段,而不是重新给LLM喂十几个例子。
可扩展性:要增加一种新操作(比如“喷涂”)?你只需要在过程树里增加一个“喷涂”分支,定义好它的标准流程节点。LLM立马就能学会如何使用它,而无需重新训练或调整整个调度模型。
性能开销低:论文中求解析取图只用了一个轻量级的FIFO启发式算法。相比于反复调用LLM进行“试错式”调度,这种方法的计算成本要低得多,且延迟可预测,这对实时工业应用至关重要。
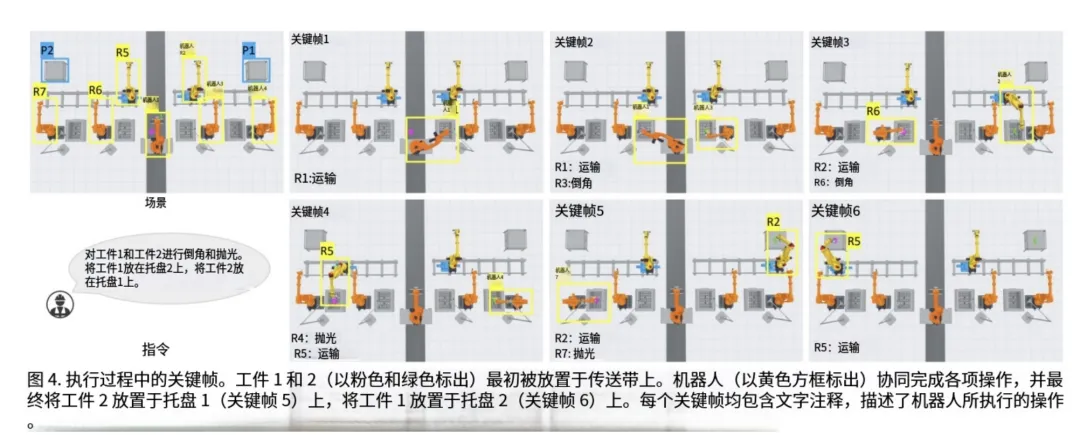
六、可视化验证:LLM真的“理解”了流程吗?
论文通过可视化手段,验证了LLM确实按照预期在工作。
从图4的执行关键帧可以看出,整个流程逻辑清晰,步骤紧凑,没有出现“撞车”或死锁。这直观证明了,通过“析取图+启发式求解”产生的调度计划,在实际执行中是可行且高效的。
而在真实的3机器人协同搬运实验中(图5),结果同样成功,验证了框架从仿真到现实的无缝迁移能力。
七、行业价值:为“工业具身智能”指明方向
这篇文章最大的价值,不在于提出了多么惊艳的新模型,而在于它提供了一个正确的“解题思路”。
它清醒地认识到:在当前乃至可预见的未来,LLM的能力边界是清晰的。与其让它“全能”,不如让它“专精”。
对比现有路线:它没有像其他研究那样,继续在“如何让LLM调度更准”上死磕(这几乎不可能完美解决),而是巧妙地引入了经典运筹学工具。这是一种“AI+OR”(人工智能+运筹学)的务实结合。
对下一代架构的启发:它启示我们,未来的工业AI系统,很可能是一个“混合式”架构:一个或多个LLM作为“认知核心”,负责理解、分解、建模;而大量的经典算法(调度、规划、控制)作为“执行核心”,负责输出确定性、最优化的结果。
正如作者在结论中所说,未来将引入“执行反馈”,形成一个闭环系统。到那时,LLM不仅能“计划”和“教学”,还能“复盘”和“优化”,一个真正智能的、自适应的“工业大脑”雏形已然显现。
最聪明的系统,不是试图用一个模型解决所有问题的系统,而是知道什么问题该交给“思考”,什么问题该交给“计算”的系统。
IMR-LLM,迈出了这坚实的一步。
参考资料
论文标题:IMR-LLM: Industrial Multi-Robot Task Planning and Program Generation using Large Language Models
核心作者:Xiangyu Su, Juzhan Xu, Oliver van Kaick, Kai Xu, Ruizhen Hu
所属机构:深圳大学, 速腾聚创(SpeedBot Robotics), 卡尔顿大学, 中国科学院
论文链接:https://arxiv.org/abs/2603.02669
相关基准数据集:IMR-Bench (基于KunWu平台构建)
【标准化版权与免责声明】
版权说明:本文为对应学术论文的二次科普解读内容,仅用于非商用的学术交流、技术科普目的,属于《中华人民共和国著作权法》规定的合理使用范畴。原论文的所有著作权、知识产权归原作者、原发布机构 / 期刊所有,本文不侵犯原作品的任何合法权益。内容说明:本文解读内容仅代表作者个人观点,不代表原论文作者、所属机构的官方立场与观点。若本文存在对原论文的解读偏差,一切以原论文官方发布的原文内容为准。商标与主体声明:本文中提及的所有机构名称、品牌名、商标、产品名称,均为其各自权利人所有,仅用于客观介绍研究背景,不代表任何官方授权、合作、背书关系。免责声明:本文内容仅为学术科普与技术交流使用,不构成任何技术落地、商业投资、产品选型、决策制定的建议,本文作者不对任何基于本文内容做出的决策承担任何责任。本文不对原论文研究成果的科学性、有效性、商业价值做任何明示或暗示的担保。转载与使用说明:未经原论文著作权人与本文创作者的书面授权,任何机构、个人不得将本文内容用于商用、二次转载、篡改、洗稿或其他侵权用途,违者将依法追究相关法律责任。文章生成提示词v10