近日,中国农业科学院深圳农业基因组研究所李奎等研究团队在bioRxiv上发表题为“BOLE: a knowledge-enhanced multi-agent AI framework for autonomous genomic breeding analysis”的论文。这篇论文介绍了 BOLE(伯乐),一个面向基因组育种智能分析的知识增强型多智能体AI框架,能够将用户高级分析意图自动转化为可验证的执行工作流,实现了全基因组关联分析、遗传力估计、种质评价与基因组选择等核心育种任务的端到端自主分析,显著降低了基因组育种的技术门槛并提升了分析的可复现性。

背景与意义
研究背景
- 数据爆炸但应用困难:高通量基因型和表型数据的快速积累推动了基因组育种的发展,全基因组关联分析(GWAS)、基因组选择(GS)等方法已成为现代育种的核心技术。
- 实际应用瓶颈:尽管统计方法和软件工具日趋成熟,但实际操作中需要协调使用异质性的命令行工具、统计环境和自定义脚本,对数据格式、参数设置和软件依赖有严格要求。
- 专家依赖问题:育种研究者不仅需要数量遗传学领域知识,还需具备高级计算技能来手动设计、调整和维护复杂分析流程,这限制了技术的可及性和可扩展性。
现有解决方案的局限
- 现有的工作流管理平台(如Nextflow、Galaxy)大多依赖预定义的静态流程或需要手动配置分析步骤。
- 用户仍需自行选择合适方法、解决数据兼容性问题、调整实验设计,难以实现真正的自动化。
BOLE的创新价值
- 引入多智能体系统(MAS)范式,实现分布式推理、任务分解和自主决策。
- 将工作流构建从"手动工程任务"转变为"推理问题",弥合方法学创新与实用化应用之间的鸿沟。
研究方法
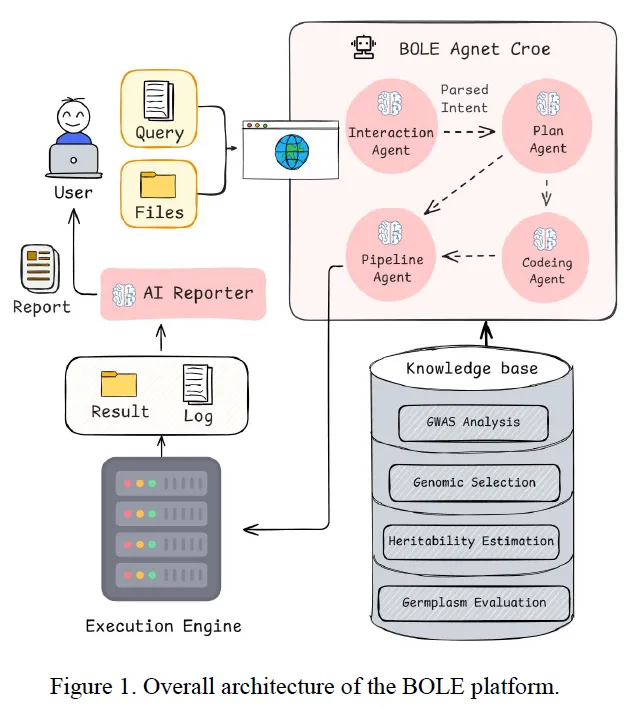
2.1 系统架构与多智能体框架
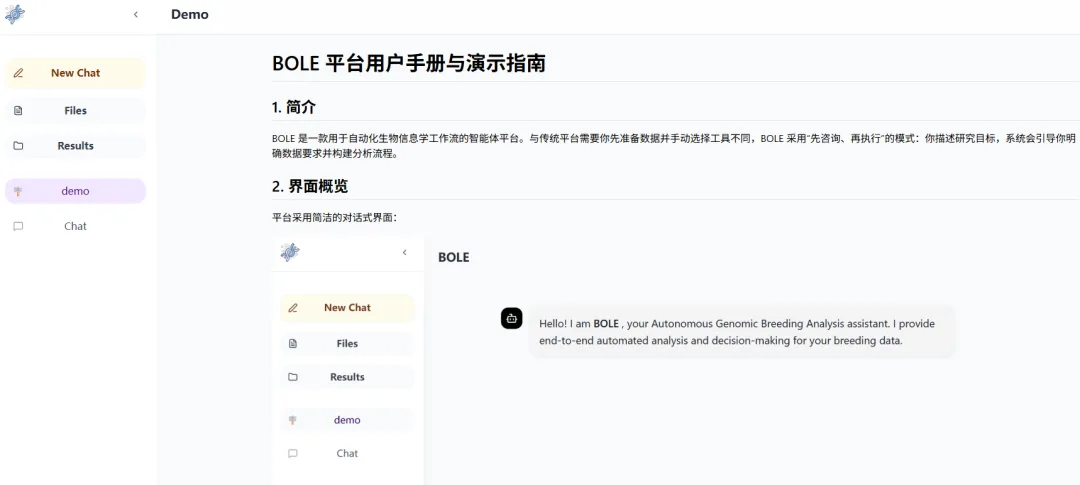
BOLE采用基于Web的多智能体架构,包含四个核心智能体:
| |
|---|
| 交互智能体 | |
| 规划智能体 | |
| 流程组装智能体 | 自动解决数据格式不匹配问题,插入必要的中间转换步骤 |
| 代码生成智能体 | 动态合成R/Python/Bash脚本,处理自定义分析和可视化需求 |
技术栈:
后端使用FastAPI框架,前端采用React+Vite构建,提供终端式执行监控界面和自然语言交互环境。
2.2 大语言模型的集成
- 使用DeepSeek和Qwen系列开源大模型作为推理组件
- 关键约束设计:LLM不作为分析逻辑的自主执行器,而是在结构化知识库的约束下运行
- 所有决策必须符合输入-输出契约、软件依赖和领域特定规则,确保可重现性
- 模型无关性:支持替换不同LLM后端而不改变工作流逻辑或分析结果
2.3 育种知识库的形式化
构建了结构化的JSON格式知识库,每个分析模块包含:
- 脚本元数据:ID、任务类别(GWAS/GS/QC等)、描述
- 输入规范:数据类型(基因型/表型)、格式(PLINK/VCF/CSV)、必需字段
这种形式化将传统生物信息学脚本转化为可互操作的计算构建块,支持自主组装复杂分析流程。
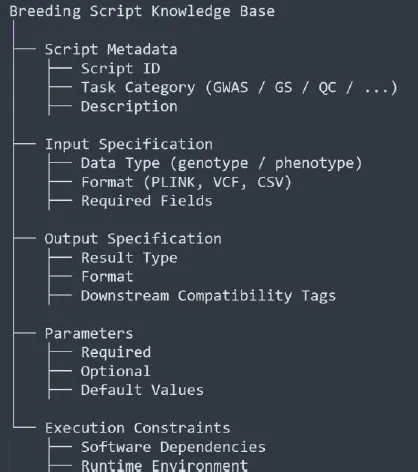 图2. BOLE使用的育种脚本知识库形式化结构。
图2. BOLE使用的育种脚本知识库形式化结构。2.4 核心分析模块实现
集成了行业标准生物信息学工具:
- GWAS:PLINK(线性回归)、GCTA(混合模型线性关联MLMA),自动生成曼哈顿图和显著位点识别
- 基因组选择:BayesA/B/C、BRR、BL、GBLUP等多种统计模型,通过K折交叉验证评估预测准确性
- 遗传力估计:基于线性混合模型,支持仅表型数据(REML)和基因型数据(基因组关系矩阵)两种模式
- 种质评价:使用ADMIXTURE进行无监督聚类,自动通过交叉验证误差分析选择最优祖先群体
研究结果
3.1 从用户意图到可执行工作流的自主转换
- BOLE接受抽象任务描述,通过多智能体协调自主构建完整工作流
- 规划智能体将请求分解为原子目标,查询知识库识别兼容模块
- 动态推断中间处理步骤(如基因型质控、格式协调、数据验证)
- 无需预定义静态流程,展示了对异质工具的推理能力和对不同数据条件的适应性
3.2 跨核心功能模块的端到端分析
从原始基因型和表型数据出发,BOLE自主执行了:
- 遗传力估计:基于基因组关系矩阵计算遗传贡献(图4A)
- 种质评价:生成ADMIXTURE群体结构分析结果(图4B)
- 基因组选择:协调多种预测模型,输出标准化交叉验证下的预测准确性指标(图4C)
- GWAS分析:生成曼哈顿图,识别与目标性状相关的位点(图4D)
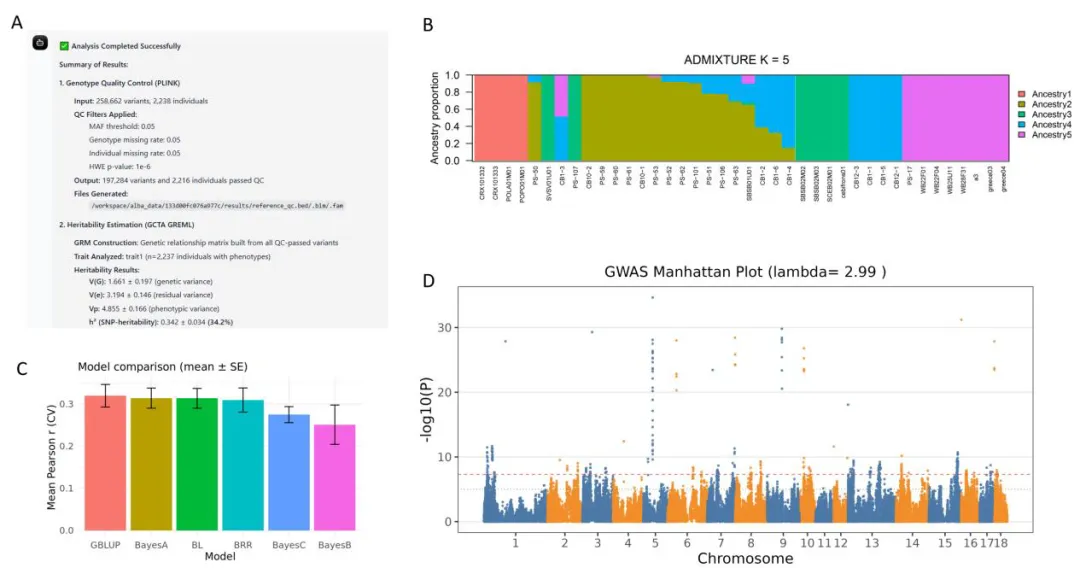 图4 BOLE在核心基因组育种模块中生成的代表性输出结果。
图4 BOLE在核心基因组育种模块中生成的代表性输出结果。所有分析在单一自主工作流中完成,模块间无需人工干预或重新配置。
3.3 自主工作流的一致性与可重现性
- 重复运行相同分析意图和数据集,系统始终生成相同的工作流结构
- 执行产物(中间文件、最终结果)被保存并可追溯(图5)
- 产物感知执行模型支持每个分析步骤的透明检查,促进可重现研究实践
3.4 动态跨任务工作流组合
设计了多阶段育种分析场景验证灵活性:
- 第一阶段:用户请求目标性状的GWAS分析,BOLE自主构建并执行完整关联分析流程
- 第二阶段:用户基于GWAS结果请求GS分析,BOLE推理识别可用的中间产物,验证数据兼容性,组装包含上游GWAS输出的可执行GS工作流
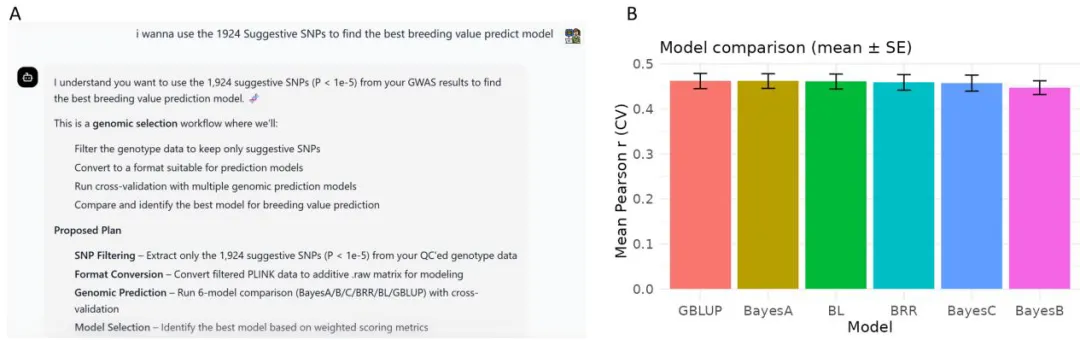 BOLE中的自主跨任务工作流规划与执行
BOLE中的自主跨任务工作流规划与执行结果表明BOLE支持基于用户意图和中间结果的动态跨任务推理,超越了孤立的特定任务工作流,能够适应真实育种场景中常见的探索性和迭代性分析需求。
讨论
主要贡献
- 从固定流程到意图驱动编排:传统系统要求用户预先设计分析序列,BOLE基于用户意图和知识库约束动态合成工作流,同时保持可重现性。
- LLM的约束性使用:LLM作为受约束的推理组件而非无约束的分析逻辑生成器,所有输出必须符合确定性规范,确保系统级确定性而非自由形式的语言生成。
- 非固定跨任务工作流支持:能够基于中间输出自主推理并组装兼容的下游工作流,无需预定义的复合流程,支持真实育种中的探索性分析。
- 产物感知执行与可追溯性:每个分析步骤的中间文件、参数、日志和动态生成脚本均被保存,支持方法学透明度和结果审计。
局限性
- 不替代专家知识:BOLE旨在降低技术应用门槛,而非取代育种或统计遗传学专业知识,也不提出新的分析模型。
- 知识库依赖性:系统性能和分析广度受限于知识库的完整性和质量,扩展到新领域需要精心策划兼容脚本和元数据。
- 需持续验证:当前实现已在核心基因组育种任务中证明稳健性,但大规模部署和更广泛的社区采用需要持续验证和扩展。
未来展望
BOLE代表了向智能、自主基因组育种分析迈进的一步,为智能生物信息学系统的未来发展提供了基础,为更可及、更可重现的基因组育种提供了可扩展的路径。
可用性
- 在线服务:http://114.80.39.6:8089/
- 预印本发布:bioRxiv,2026年2月6日,DOI: 10.64898/2026.02.04.703673