深圳法院的AI辅助审判系统,已经处理超过60万宗案件了。
我的第一反应不是"AI要取代法官",而是——
这玩意儿到底用了什么技术?
60万案件不是小数目,民事、刑事、行政案件各有各的复杂,AI能处理成这样,背后一定有些东西。
我扒了几天资料,跟几个做过法律IT的朋友聊了聊,今天把干货整理出来,给程序员兄弟们看看。
1️⃣ 先说个冷知识:法院文书,可能是你见过最复杂的"文本"
普通人以为法律文书就是"起诉书 + 判决书",写清楚谁告谁就行了。
Too young。
来,给你感受一下什么叫地狱级文本处理:
"被告人张某于2023年5月间,在深圳市南山区某商场地下停车场,趁被害人李某遗忘锁车之机,窃取车内现金人民币12000元及手机一部,其行为已构成盗窃罪,依法应予追究刑事责任。"
看到了吗?
时间、地点、人物、行为、金额、罪名,全部压缩在一句话里,语法结构还贼复杂。
更别说还有大量法律术语:拘役、缓刑、累犯、共同犯罪、加重情节……
让AI"读懂"这些文书,难度不亚于读懂一段没有注释的生产级Java代码。
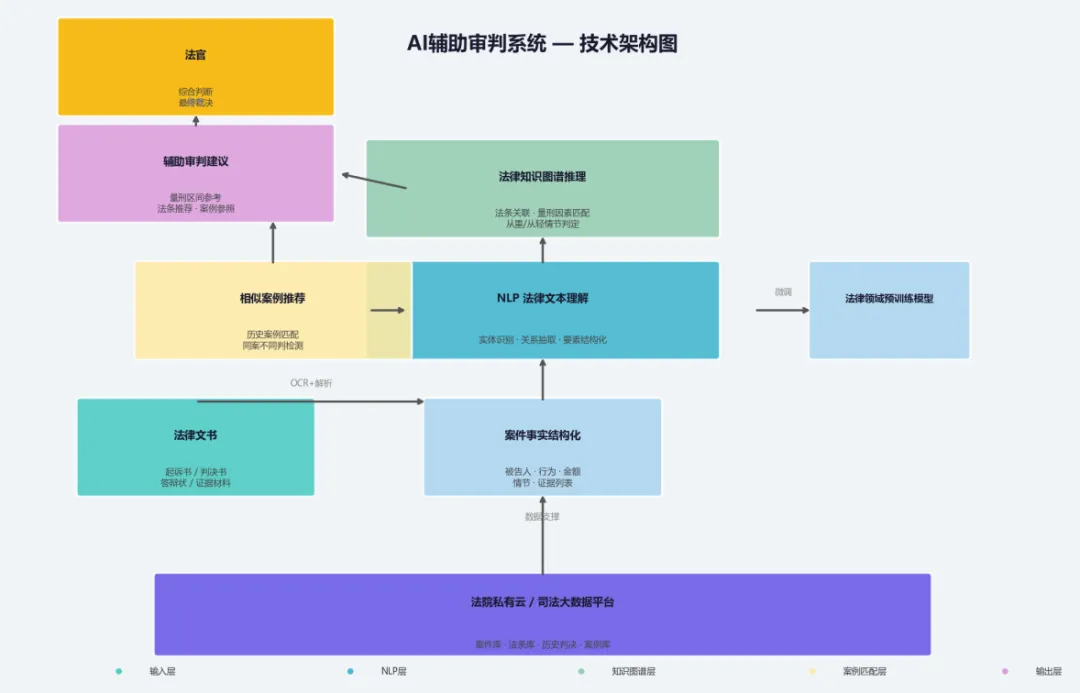
2️⃣ AI审判系统到底干了什么活?拆开看三层
我扒了公开资料和几个行业报告,把整个系统拆成了三层:
🔵 第一层:NLP 法律文本理解(让AI"识字")
这一步是所有后续的基础——系统得先"读懂"文档,才能干活。
但法律文本有个很恶心的问题:专有名词贼多、句式贼绕。
普通NLP模型拿来直接用,效果惨不忍睹。
行业内的做法一般是:先拿通用的语言模型,在大量判决书、法条、案例库上做微调,训练出一个法律领域专用版本。
简化版的核心逻辑大概是:
# 法律文书关键要素抽取(简化示意)def extract_criminal_facts(text): # 1. 实体识别:谁、在哪、偷了什么、多少钱 entities = legal_ner_model.predict(text) # 输出:{'被告人': '张某', '地点': '南山区停车场', # '行为': '盗窃', '金额': '12000元'} # 2. 关系抽取:提取"趁...之机""窃取"这类法律关系 relations = legal_re_model.extract(text) # 3. 要素结构化:输出结构化事实清单 structured_facts = build_fact_graph(entities, relations) return structured_facts
说白了就是:实体识别 + 关系抽取 + 要素结构化,把一坨自然语言文字,变成机器能理解的结构数据。
这一层做不好,后面全是白搭。
🟢 第二层:知识图谱——法条之间的"关系网"
这一层是我觉得最有意思的。
法院判案不是简单的"盗窃罪→判3年",而是要综合考虑一堆因素:
有没有前科?
退赃了没有?
有没有自首情节?
被害人有没有过错?
每一条都可能影响最终量刑,而且这些因素之间还有交叉影响。
行业里通常会构建一个法律知识图谱:
当系统识别出案件事实后,自动往图谱里匹配节点,输出类似这样的参考:
"这个案子有自首情节 + 已退赃 + 取得被害人谅解,建议从轻处理"
注意:是建议,最终拍板还是法官的事。
🔴 第三层:案例推荐——找"长得像"的案子
这一层解决的是司法实践里一个很现实的问题:
类似案件,不同法院判下来可能差很多。
同一个盗窃罪,有的地方判6个月,有的地方判1年。
同案不同判多了,老百姓看着就容易嘀咕:"法院是不是看心情判的?"
系统的做法是:把新案件的结构化事实往历史案例库里一丢,找到相似度最高的N个案子,给法官参考:
"类似案件在深圳其他法院怎么判的,平均量刑多少"
数据透明了,判决依据清晰了,质疑声也少了。
3️⃣ 我顺手画了一张架构图
整个系统跑下来,核心逻辑大概是这样:
简单说就是:
文书输入 → NLP解析 → 知识图谱推理 → 案例匹配 → 辅助建议 → 法官决策
每一层独立模块,底层是法院私有云,数据不出内网——这个很重要,法律数据敏感性高,安全要求不是一般的高。
4️⃣ 我看完后最大的感受
扒完这套系统,我最想说的一句话是:
AI在法律领域,目前最正确的姿势就是"辅助",而不是"替代"。
为什么?
因为判决不只是逻辑运算,还涉及:
社会影响怎么考量
个案公平性怎么平衡
道德和情感的边界在哪
被告人的实际处境要不要考虑
这些东西,AI算不出来。
但AI能做的是:把法官从繁琐的文书阅读、法条检索、案例匹配里解放出来,让他们有更多精力去思考"公平"本身。
这才是技术该有的位置。
扒资料的时候我一直在想一个问题:
如果AI推荐的量刑建议,和法官的判断不一致——听谁的?
我查了半天,业内好像也没有标准答案。
你有没有想法?评论区聊聊,这个问题比代码有意思多了 😄
老林 | 混过北上广、踩过无数坑的前浪关注我,带你用普通人的方式学技术