
🐉 龙哥读论文知识星球来了!还在为图像模糊、扭曲而烦恼吗?想学习更多像GSTurb这样“熨平”湍流的黑科技?星球每日无上限更新图像增强、3D重建、AI去噪等前沿论文与代码,让你像高斯泼溅一样高效吸收知识!👇扫码加入「龙哥读论文」知识星球,前沿干货、实用资源一站式拿捏~
龙哥推荐理由:
这篇论文将火爆的3D高斯泼溅技术首次引入大气湍流复原领域,思路新颖且效果拔群。它巧妙地将复杂的物理退化过程映射到高斯参数上,通过优化这些参数来“逆向工程”出清晰图像。方法设计扎实,实验充分,在合成和真实数据集上都取得了显著的性能提升,为图像复原领域提供了一个强有力的新工具,非常值得关注和学习。
原论文信息如下:
论文标题:
GSTurb: Gaussian Splatting for Atmospheric Turbulence Mitigation
发表日期:
2026年02月
发表单位:
深圳大学,澳门大学等
原文链接:
https://arxiv.org/pdf/2602.22800v1.pdf
开源代码链接:
https://github.com/DuhlLiamz/3DGS_turbulence/tree/main
想象一下,你拿着高清望远镜对准远处一栋大楼,结果看到的画面却像隔着一锅沸腾的开水——楼体扭曲变形,细节糊成一团。😫 这就是大气湍流(Atmospheric Turbulence)给长距离成像带来的噩梦。
大气中随机变化的气流就像无数个不断移动的“透镜”,让光线在传播路径上发生随机的偏折和扩散。最终抵达相机时,图像就遭到了双重打击:像素位移(俗称“歪斜”或 Tilt)和图像模糊(Blur)。
传统的复原方法要么分开处理这两个问题,过程繁琐且效果有限;要么依赖深度学习模型,但对大量输入图像的处理能力不足,且难以建模真实的物理退化过程。
就在大家为此头疼的时候,来自深圳大学和澳门大学的几位研究者脑洞大开:为什么不用这两年火出圈的“3D高斯泼溅”(3D Gaussian Splatting, 简称3DGS)来“熨平”湍流呢?
于是,他们提出了GSTurb——一个将光流引导的歪斜校正与高斯泼溅建模非等晕模糊相结合的创新框架。简单说,就是用一堆可调的“高斯小球”来模拟图像和湍流退化过程,然后通过优化这些“小球”的参数,逆向“泼溅”出一张清晰图像。听起来是不是很酷?🧐
湍流复原新思路:当高斯泼溅遇见大气扰动
首先,我们来快速科普一下核心武器——3D高斯泼溅(3D Gaussian Splatting, 3DGS)。这玩意儿原本是干3D场景重建的。它把一个3D场景看作由无数个“高斯小球”(一种数学上的椭圆球)组成。每个小球有自己的位置、大小、方向、颜色和透明度。渲染图像时,就把这些3D小球“泼溅”(Splat)到2D图像平面上,通过可微分的方式融合计算,得到最终像素颜色。
GSTurb的核心洞察在于:大气湍流造成的图像歪斜和模糊,恰好可以映射到这些高斯小球的参数变化上!
湍流让像素乱跑,相当于每个高斯小球的中心位置(x, y坐标)发生了随机偏移。
模糊效应(尤其是复杂的非等晕模糊)则可以看作是高斯小球的形状(由旋转和缩放参数决定)被“拉扯”和“压扁”了,其数学本质是高斯分布的协方差矩阵发生了改变。
这样一来,整个湍流复原问题就被优雅地转换成了一个优化问题:给定一批被湍流干扰的模糊、歪斜图像,我们反过去调整所有高斯小球的参数(位置、旋转、缩放等),使得由这些优化后的小球“泼溅”渲染出来的图像,能够最好地匹配那些模糊的输入图像。一旦优化完成,用优化后的小球渲染出的图像,自然就是去除了歪斜和模糊的清晰图像了!
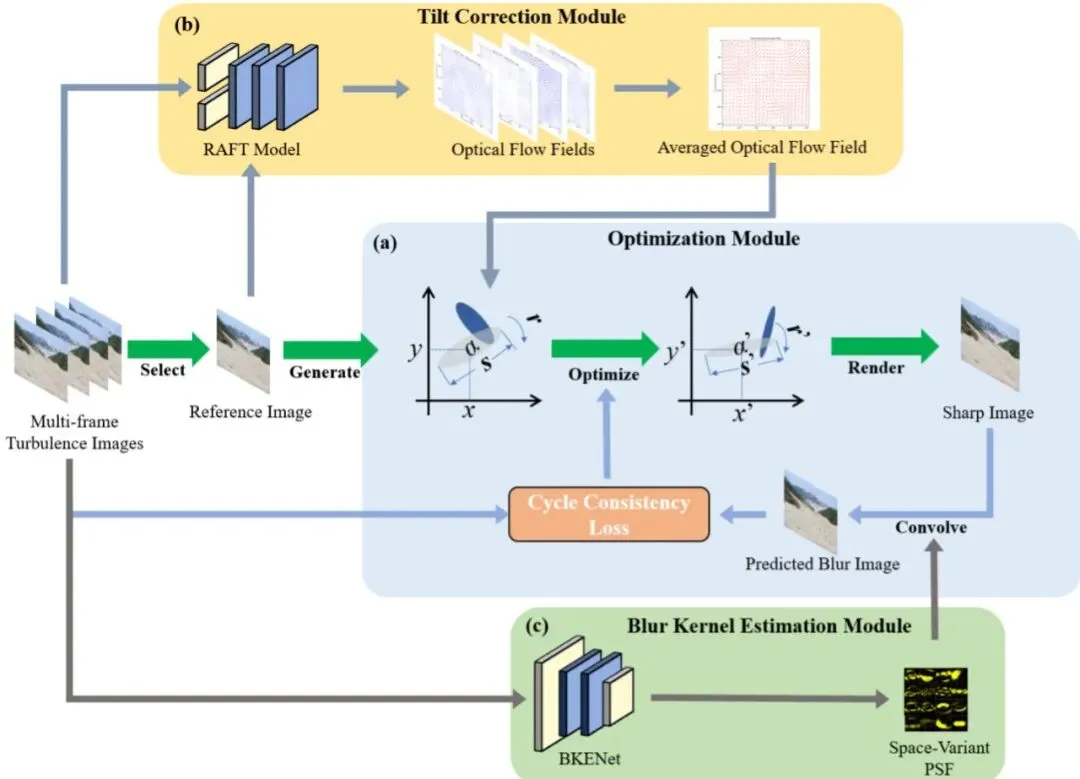
图1:高斯泼溅大气湍流复原工作流程。图1(a)展示了优化模块。图1(b)展示了歪斜校正模块。图1(c)展示了模糊核估计模块。
上图清晰展示了GSTurb的三个核心模块:优化模块是核心,负责迭代优化高斯参数;歪斜校正模块负责先给图像“掰正”;模糊核估计模块负责估算让图像变糊的“罪魁祸首”到底长什么样。
化繁为简:光流统计先验巧治图像“歪斜”
歪斜(Tilt)的本质是多帧图像之间像素的随机、无规律位移。传统方法往往假设有一帧“幸运帧”(Lucky Frame)是完全没歪斜的,然后用它作为基准去校正其他帧。但现实中,找到完美的“幸运帧”很难,而且这个方法本身也容易引入偏差。
GSTurb想出了一个更聪明的办法:利用一个统计先验知识——湍流引起的位移在时间平均上是零均值的。也就是说,像素虽然乱跑,但平均来看,它还是待在自己的“老家”。
1. 计算光流:选取一帧作为参考帧 I₀,然后使用一个强大的光流估计模型RAFT(Recurrent All-Pairs Field Transforms [11], 一种先进的深度学习光流估计架构)来计算所有其他帧相对于I₀的光流场。这个光流场就记录了每一帧每个像素相对于参考帧“跑偏”了多少。2. 求平均位移:把所有帧的光流场加起来,求个平均,得到平均位移场 F̄(p)。根据零均值先验,这个平均位移场正好就是参考帧 I₀ 自身受到的歪斜效应的反方向。3. 逆向校正:最后,把参考帧的每个像素按照平均位移场的反向移动一下,就得到了初步校正后的图像 I_correct。数学上非常简单: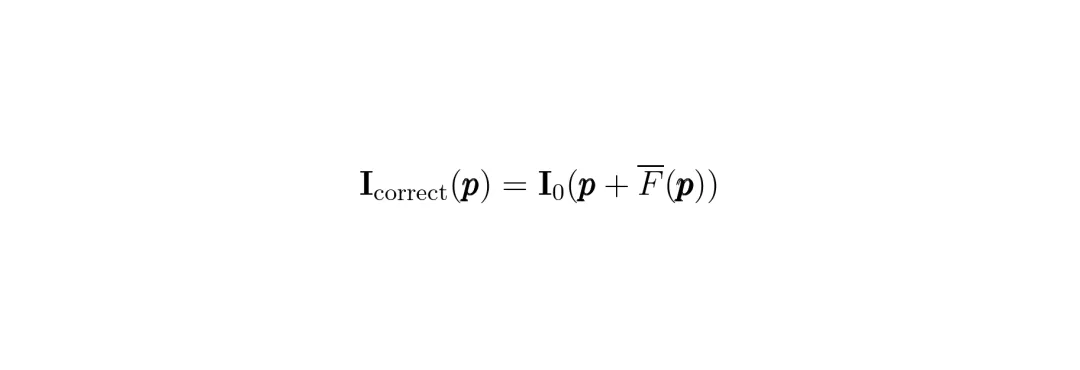 公式:校正后图像 I_correct 在像素p处的值,等于原始参考帧 I₀ 在位置 p + 平均位移 F̄(p) 处的值。
这个方法的好处是无需寻找完美的幸运帧,也不需要假设参考帧是干净的,通过多帧平均自然抵消了随机误差,计算高效且物理意义明确。校正后的图像,其歪斜程度会大大降低,为后续的模糊去除奠定了良好基础。
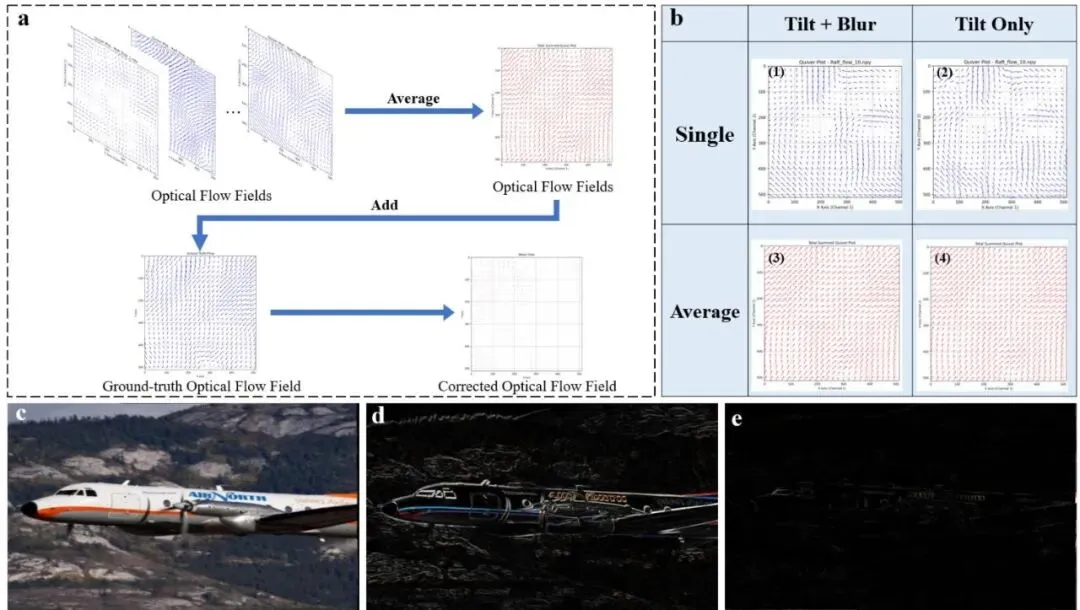
图2:歪斜校正实验结果。图2a展示了多帧光流歪斜校正的过程和实验结果。图2b展示了模糊效应对单帧光流场估计和平均光流场的影响。图2c到2e展示了光流场校正前后的图像残差。
公式:校正后图像 I_correct 在像素p处的值,等于原始参考帧 I₀ 在位置 p + 平均位移 F̄(p) 处的值。
这个方法的好处是无需寻找完美的幸运帧,也不需要假设参考帧是干净的,通过多帧平均自然抵消了随机误差,计算高效且物理意义明确。校正后的图像,其歪斜程度会大大降低,为后续的模糊去除奠定了良好基础。
图2:歪斜校正实验结果。图2a展示了多帧光流歪斜校正的过程和实验结果。图2b展示了模糊效应对单帧光流场估计和平均光流场的影响。图2c到2e展示了光流场校正前后的图像残差。
降维打击:等晕区域划分让模糊核估计不再头疼
解决了“歪斜”,接下来是更棘手的“模糊”。大气湍流引起的模糊,在大视场(Field of View, FOV)下是非等晕的(Non-isoplanatic)。这意味着图像不同区域的模糊程度和形态可能都不一样,用一个统一的模糊核(点扩散函数, PSF)去描述整个图像是行不通的。
直接为图像中每一个像素都估计一个不同的模糊核?计算量和参数量将是天文数字,完全不现实。
GSTurb的解法堪称“降维打击”:它引入了“等晕区域”(Isoplanatic Region/Patch)的概念。这是大气光学中的一个概念,指的是在这样一个角度范围内,波前畸变是近似均匀的,因此成像的模糊核可以认为是相同的。
论文根据成像距离、湍流强度等参数,计算出在特定图像分辨率下,一个等晕区域大约覆盖多少像素。对于文中的实验设置,他们发现将512×512的图像划分成32×32个等晕小块(每个小块约16×16像素)是合理的。这样一来,只需要为每个小块估计一个模糊核即可,而不是为26万多个像素分别估计!
模糊核本身也是用主成分分析(PCA)分解成101个(1个主成分 + 100个子成分)基函数的加权和来表示。这些基函数是从模拟的湍流模糊核中学到的,能有效表征湍流模糊的统计特性。
于是,模糊核估计的任务就交给了BKENet(Blur Kernel Estimation Network)。这个基于ResNeXt的神经网络,输入是经过歪斜校正的图像块,输出是每个等晕区域对应的100个子成分基函数的权重。然后加权组合,就得到了该区域的模糊核。
这一顿“降维”操作下来,需要估计的参数量从恐怖的 100 × 512 × 512 锐减到 100 × 32 × 32,足足减少了256倍! 这不仅极大地降低了计算复杂度和优化难度,也使得模型训练和推理更加稳定高效。
最后,整个优化过程通过一个循环一致性损失(Cycle-Consistency Loss)来驱动。这个损失函数的思想是:一张清晰的图像,经过估计出的模糊核变模糊后,应该能尽可能接近输入的模糊图像;反过来,输入的模糊图像,经过模糊核的“逆过程”去模糊后,也应该能尽可能接近清晰图像。通过最小化这个循环差异,可以联合优化高斯参数和模糊核估计,确保整个复原过程在物理上是自洽的。
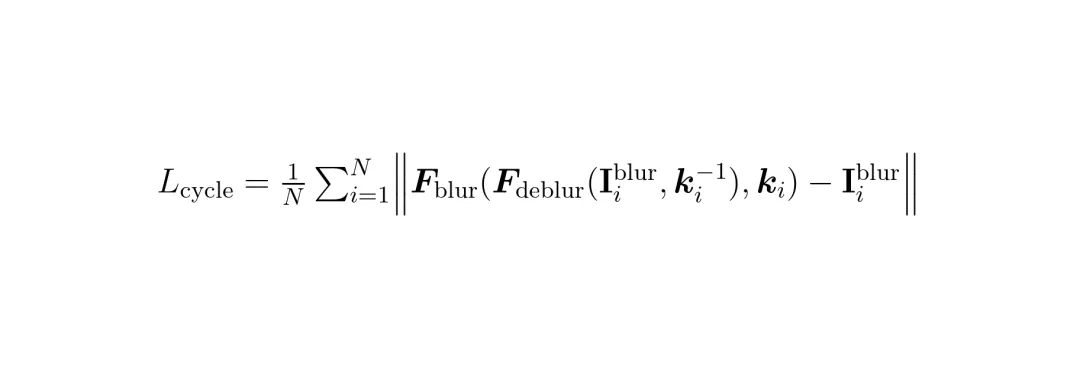 公式:循环一致性损失函数。其中 F_blur 是模糊过程, F_deblur 是去模糊过程, k_i 是第i帧的模糊核, I_i^blur 是第i帧模糊图像。
公式:循环一致性损失函数。其中 F_blur 是模糊过程, F_deblur 是去模糊过程, k_i 是第i帧的模糊核, I_i^blur 是第i帧模糊图像。
效果说话:合成与真实数据双双刷新SOTA
理论说得再好,也得用实验结果来证明。GSTurb在多个标准数据集上进行了测试,包括合成的ATSyn-static数据集和真实的CLEAR、TSRWGAN Real-World数据集。
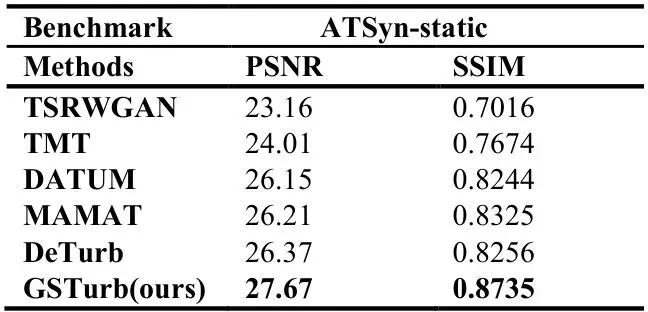
在ATSyn-static数据集上,GSTurb取得了惊人的峰值PSNR 27.67 dB和SSIM 0.8735。与之前最先进(SOTA)的方法相比,PSNR提升了1.3 dB(相对提升4.5%),SSIM提升了0.048(相对提升5.8%)。这是一个非常显著的全面性能提升。
表I:在ATSyn-static数据集上与SOTA方法的定量比较(平均PSNR/SSIM)。
我们来看一下视觉效果对比。下图左侧是清晰的真值(Ground Truth)和原始的退化图像。可以看到,GSTurb复原出的图像(最右侧)在清晰度、细节恢复和边缘锐利度上都明显优于其他方法,比如TSRWGAN、TMT、DATUM、MAMAT和DeTurb。
图3:在ATSyn-static数据集上的复原结果对比。(a)和(e)分别是真值和原始退化图像。(b)到(h)分别是TSRWGAN, TMT, DATUM, 原始输入, MAMAT, DeTurb和我们GSTurb的复原结果。
在真实的CLEAR数据集上,虽然没有绝对真值,但通过与其他方法复原结果的视觉对比,GSTurb同样展现出了更强的去模糊和细节恢复能力,图像看起来更自然、锐利。
图4:在CLEAR数据集上的复原结果对比。排列顺序与图3类似,GSTurb的结果(h)视觉效果最佳。
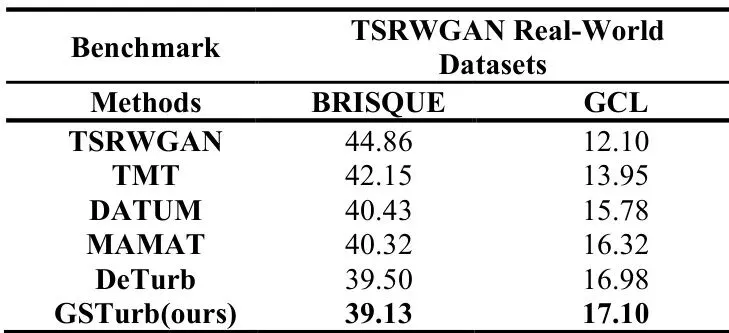
在另一个真实数据集TSRWGAN Real-World上,论文使用了无参考图像质量评价指标BRISQUE(分数越低越好)和GCL(Global Contrast Loss, 全局对比度损失,也是越低越好)进行评估。GSTurb在这两个指标上也全面领先于其他对比方法。
表III:在TSRWGAN Real-World数据集上与SOTA方法的定量比较(平均BRISQUE/GCL)。
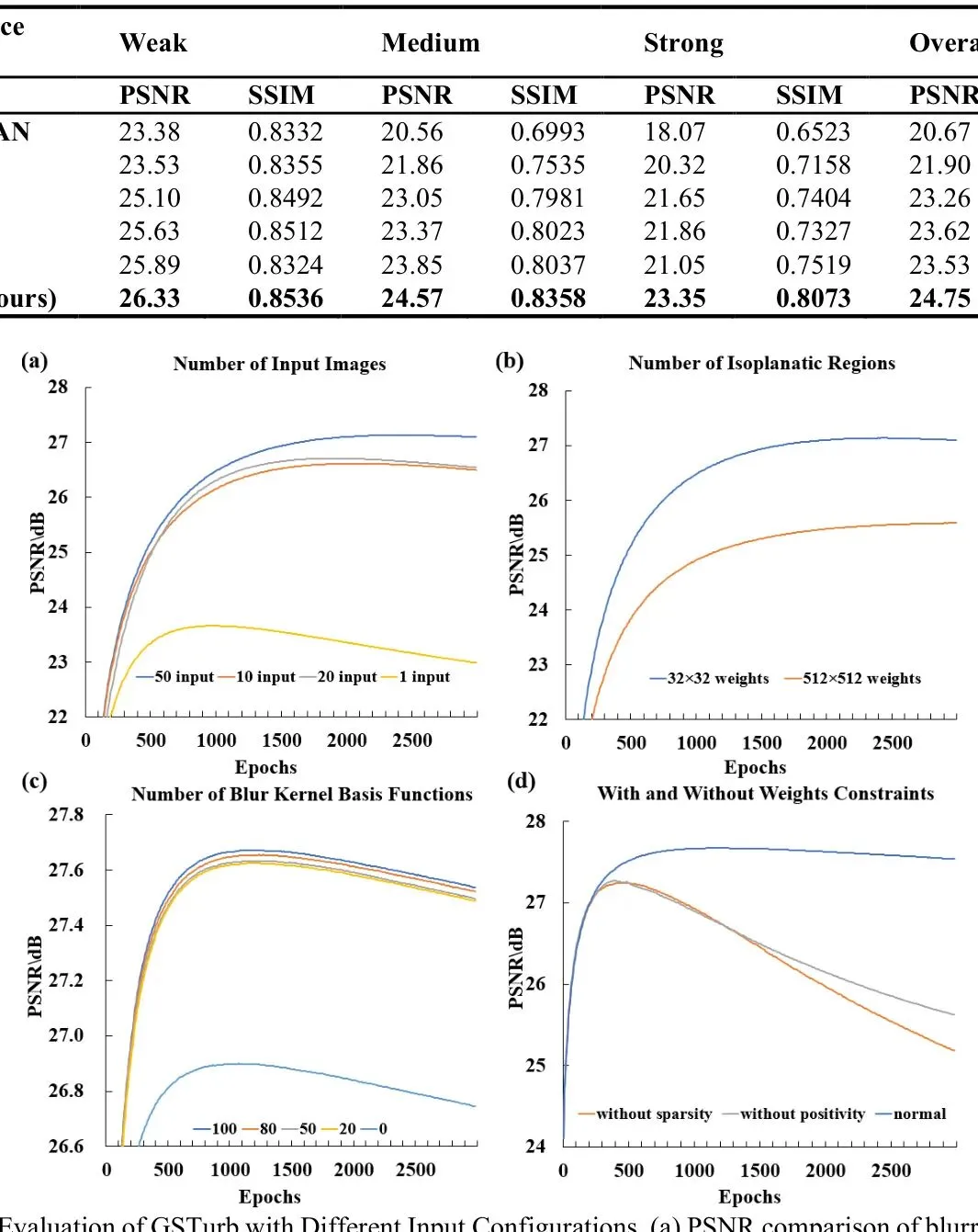
论文还进行了一系列消融实验,验证了各个模块设计的有效性。例如,输入更多帧图像(如50帧)能获得更好的复原质量;使用等晕区域划分比逐像素估计效果更好且更高效;对模糊核权重施加非负约束和稀疏性正则化也能带来性能提升。
图5:不同输入配置下GSTurb的性能评估。(a)不同输入图像数量(1,10,20,50帧)的模糊图像复原PSNR对比。(b)不同等晕区域数量(32x32 vs 512x512)的PSNR对比。(c)不同模糊核基函数数量的PSNR对比。(d)不同权重约束下的PSNR对比。
局限与展望:静态场景的突破与动态世界的挑战
尽管GSTurb在静态场景的湍流复原上表现惊艳,但作者也坦率地指出了其当前的局限性以及未来的挑战。1. 静态场景假设:目前的GSTurb主要针对静态场景(如静止的建筑物、标靶)。它依赖于多帧图像中场景内容不变,才能有效地利用时间统计信息进行歪斜校正和联合优化。如果场景中存在显著运动的目标,当前方法可能会失效或产生伪影。2. 计算成本:虽然等晕区域划分大大降低了参数量,但基于高斯泼溅的优化过程本身仍然需要迭代计算,相比一些纯前向推理的深度学习模型,其运行时间会更长,对计算资源有一定要求。3. 参数敏感性:等晕区域大小的划分、PCA基函数的数量等超参数需要根据具体的成像条件和湍流强度进行设定。如何实现更自适应的参数选择是一个有待研究的方向。
展望未来,一个激动人心的方向是将GSTurb框架扩展到动态场景。或许可以结合动态3D高斯泼溅(Dynamic 3DGS)的技术,为场景中的运动物体也建模其轨迹和形变,从而实现“湍流”与“真实运动”的解耦。此外,探索更轻量化的优化策略,以及将部分模块(如BKENet)与高斯优化过程进行更紧密的端到端联合训练,也可能进一步提升效率和效果。
龙迷三问
高斯泼溅(Gaussian Splatting)具体是什么?简单说,它是一种用一大堆“高斯小球”来表示3D场景的方法。每个小球像一团有颜色、有形状、半透明的“雾”。渲染2D图像时,把这些3D小球投影到屏幕上并融合起来。它的优势是渲染速度快(特别是配合GPU),且整个过程是可微分的,方便用梯度下降法优化这些小球的参数(位置、大小、颜色等)来拟合目标图像或场景。
光流(Optical Flow)在这里起什么作用?光流是描述视频中相邻两帧图像之间像素运动(位移)的场。在GSTurb中,利用RAFT模型计算多帧湍流图像相对于某一参考帧的光流,这些光流就量化了每帧图像因湍流造成的“歪斜”程度。然后利用湍流位移在时间上均值为零的统计特性,对光流场求平均并反向校正,从而有效地去除歪斜。
等晕区域(Isoplanatic Region)为什么重要?这是连接物理与算法的关键桥梁。在大视场成像中,湍流模糊在空间上是变化的,直接逐像素估计模糊核不现实。等晕区域是基于大气物理定义的一个小范围,在这个范围内模糊可被认为是相同的。利用这个概念,GSTurb将图像划分成多个等晕小块,只需为每个小块估计一个模糊核,从而将问题从一个超高维的、病态的问题,降维成一个可处理的、参数化的问题,是方法能成功的关键之一。
如果你还有哪些想要了解的,欢迎在评论区留言或者讨论~龙哥点评
论文创新性分数:★★★★★
首次将3D高斯泼溅(3DGS)这一前沿技术引入大气湍流复原领域,构思新颖。巧妙地将物理退化过程映射到高斯参数优化问题,并创新性地结合光流统计先验和等晕区域划分来简化难题,整体思路极具原创性。实验合理度:★★★★☆
在合成和多个真实世界数据集上进行了充分验证,对比了当前主流SOTA方法,并进行了详细的消融实验分析各模块贡献。实验设计全面,结果可信。扣一星在于对动态场景的测试和对比略显不足。学术研究价值:★★★★★
为图像复原和计算摄影领域提供了一个强有力的新范式。证明了3DGS这类可微分渲染技术在解决复杂逆问题(如非等晕去模糊)上的巨大潜力,具有很强的启发性和研究价值,预计会带动一批后续工作。稳定性:★★★☆☆
在静态场景和给定成像条件下表现稳定且优异。但由于依赖迭代优化和物理参数(如等晕角)的估计,对于不同湍流强度、场景内容的变化,其稳定性和鲁棒性可能需要进一步验证和调参。适应性以及泛化能力:★★★☆☆
方法设计紧密结合了大气湍流的物理特性(零均值位移、等晕区域),这使其对真实湍流数据有较好的泛化能力。但当前框架主要针对静态场景,对动态场景和极端湍流条件的适应性是主要短板。硬件需求及成本:★★☆☆☆
需要GPU进行光流估计和高斯泼溅的迭代优化,尤其是优化过程可能需时较长,难以满足实时性要求。计算成本显著高于纯前向推理的深度学习模型。复现难度:★★★★☆
论文方法描述清晰,提供了开源代码,这是巨大加分项。但方法涉及多个模块(RAFT光流、BKENet训练、GS优化),整个流程的搭建和调参对复现者仍有一定技术门槛。产品化成熟度:★★☆☆☆
目前更偏向于一个研究型框架。对于静态、离线处理的长距离监控或科学观测(如天文、远程传感)有应用潜力。但要达到高鲁棒、自适应、实时或准实时的产品级应用,还需要在算法效率、动态场景处理、参数自适应等方面做大量工程化工作。可能的问题:本文是一篇优秀的研究论文,但以顶会标准来看,对方法在更极端或复杂条件(如强烈动态场景、与传感器噪声耦合)下的失效模式分析可以更深入。另外,将等晕区域大小作为一个可学习的或自适应参数,可能比固定划分更具泛化性。[1] 论文原文: Hanliang Du, Zhangji Lu, et al. "GSTurb: Gaussian Splatting for Atmospheric Turbulence Mitigation". arXiv:2602.22800v1, 2026.[2] 开源代码: https://github.com/DuhlLiamz/3DGS_turbulence/tree/main[3] Kerbl B, Kopanas G, Leimkühler T, et al. "3D Gaussian Splatting for Real-Time Radiance Field Rendering". ACM TOG, 2023. (3DGS原始论文)[4] Teed Z, Deng J. "RAFT: Recurrent All-Pairs Field Transforms for Optical Flow". ECCV, 2020. (光流估计模型)[5] Xie S, Girshick R, Dollár P, et al. "Aggregated Residual Transformations for Deep Neural Networks". CVPR, 2017. (ResNeXt网络结构)*本文仅代表个人理解及观点,不构成任何论文审核或者项目落地推荐意见,具体以相关组织评审结果为准。欢迎就论文内容交流探讨,理性发言哦~ 想了解更多原文细节的小伙伴,可以点击左下角的"阅读原文",查看更多原论文细节哦!

还在为图像模糊、扭曲而烦恼吗?想和更多图像处理大神交流前沿技术?
欢迎加入龙哥读论文粉丝群,
扫描下方二维码或者添加龙哥助手微信号加群:kangjinlonghelper。
一定要备注:研究方向+地点+学校/公司+昵称(如 图像处理+上海+清华+龙哥),根据格式备注,可更快被通过且邀请进群。










 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
