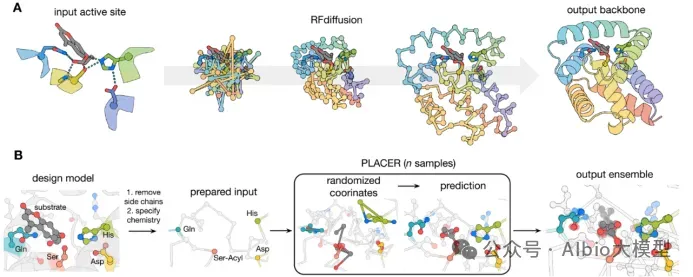
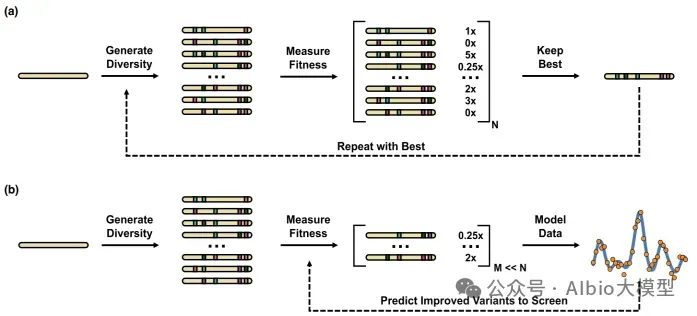
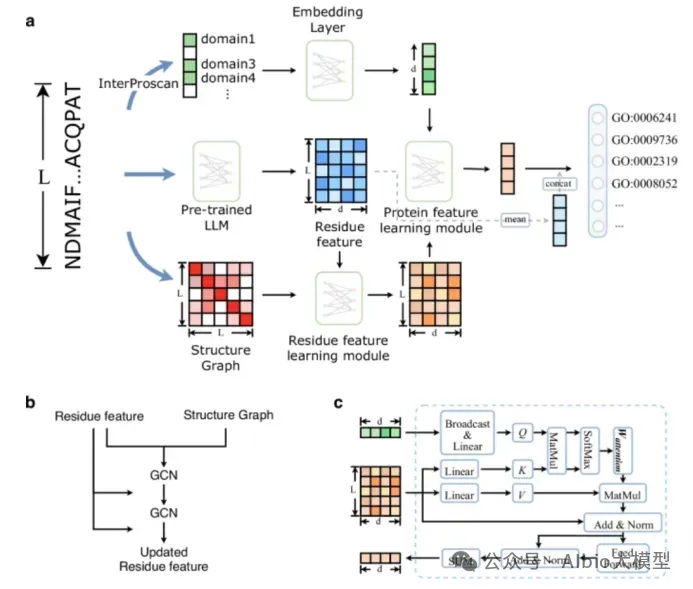
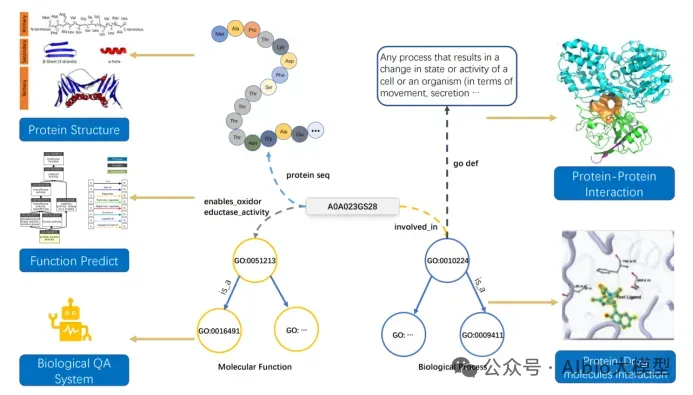
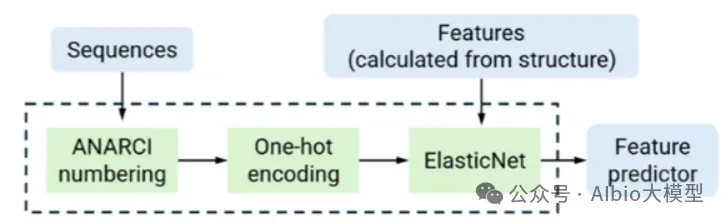
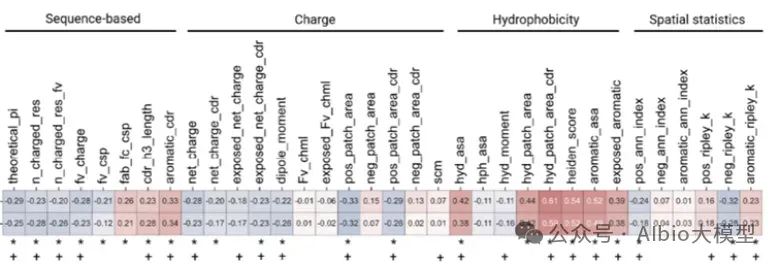
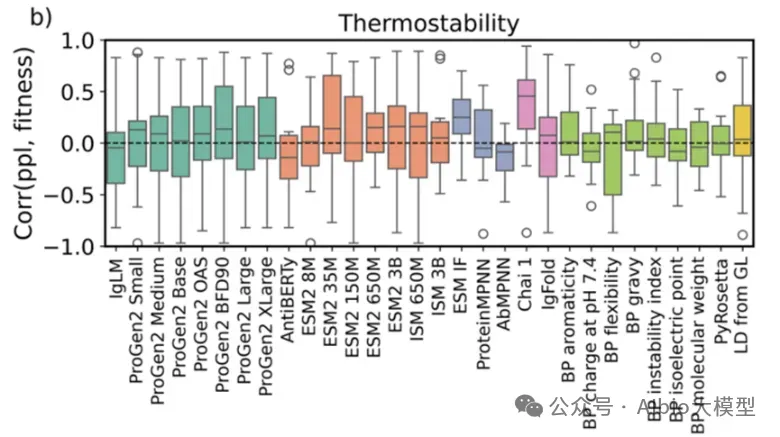
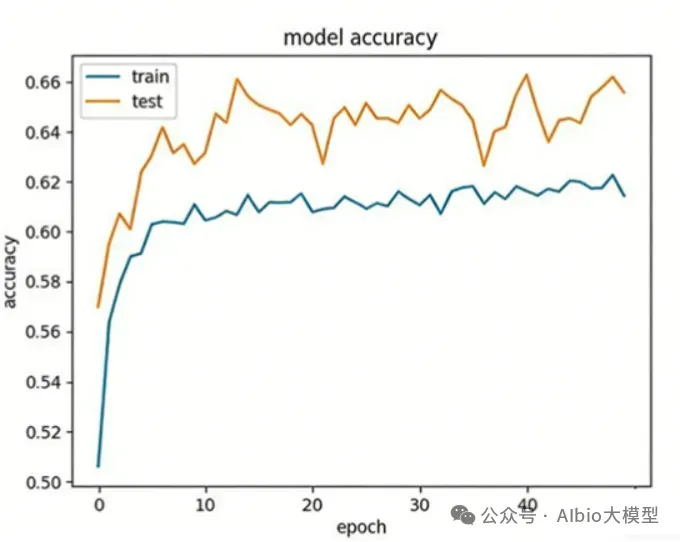
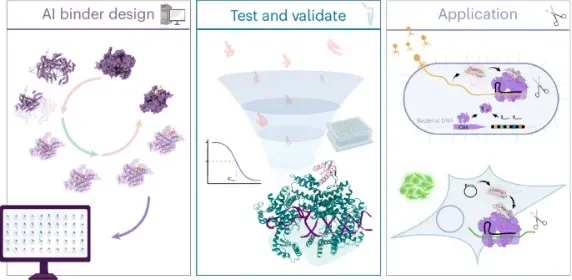
从头开始构建一个活细胞需要克服一个长期未解的瓶颈:协调核心功能模块的时空整合。为了突破这一障碍,亚洲合成细胞倡议提出了一项策略,即先开发核心功能模块,然后通过建立一个集中的人工智能(AI)驱动的生物铸造厂实现系统层面的整合。
合成生物学的一个定义目标是自下而上地构建一个合成细胞——一个能够自主基因表达、全面代谢、自我复制以及持续生长和分裂的磷脂包封系统。通过实现精确、可预测的功能并加深我们对生命的机械理解,合成细胞在生物制造、医学和生物技术方面具有巨大潜力。这一愿景激发了全球研究界的动力,欧洲和美国均有开创性举措,如MaxSynBio、Build-a-Cell、BaSyCand EVOLF等,通过模块化设计和跨学科合作奠定了关键基础。与此同时,亚洲也发展了独特且高度互补的能力,对合成细胞的构建至关重要。为了利用这些集体专业知识并加速全球合成细胞工作的发展,SynCell亚洲倡议汇聚了中国、日本、韩国、新加坡、泰国和马来西亚的100多个研究小组。在此,我们概述了合成细胞发展中的关键科学和组织挑战,并规划了联合体实现完全自主、可复制的合成细胞的战略轨迹。
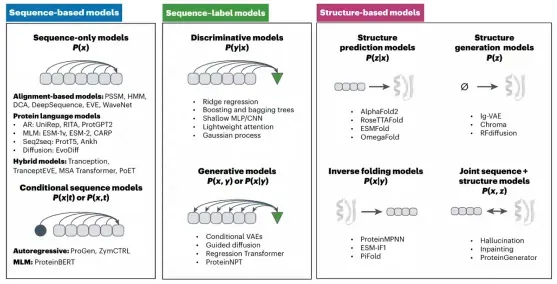
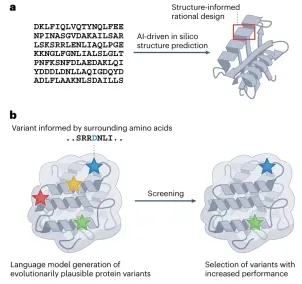
01. AI蛋白质设计
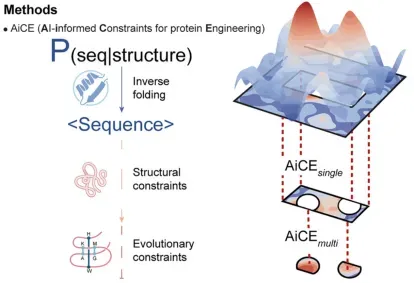
02 AI+多肽设计
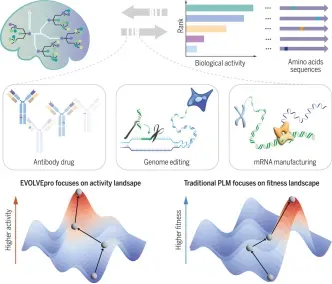
03. AI+抗体设计
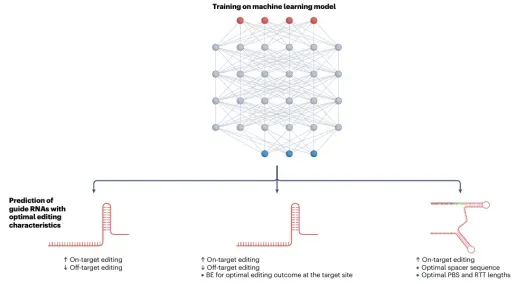
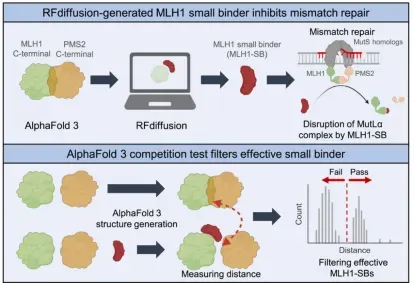
04. AI+基因编辑
05.AI构建虚拟细胞
主讲老师在学术界和工业界都有丰富算法开发和应用经验,博士毕业于国内顶尖课题组,从事蛋白质结构预测和蛋白质设计的研究工作,相关工作成果已在Cell Systems、Angew. Chem. Int. Ed.、JCIM等国际知名期刊发表论文。目前在知名药企担任高级研究员,主导AI驱动的大分子药物设计平台开发与团队管理。
01
AI蛋白质设计课表
02
通过课程学习您将得到
多种蛋白质设计方法、深度学习酶设计、深度学习抗体设计等流程!让学员快速学会David baker核心方法!培训理论结合实操!提供服务器使用!通过详细讲解实操AlphaFold2、AlphaFold3以及pymol和Foldseek等软件让学员学会蛋白质结构预测!通过详细讲解实操ESM系列(ESM-1b、ESM-1v、ESM2、ESMC、ESM3)、GPT的生成模型ProGen让学员学会蛋白质大语言模型!通过详细讲解实操ProteinMPNN、LigandMPNN、ThermoMPNN、Rfdiffusion等软件让学员学会多种蛋白质设计方法!最后通过深度学习酶设计与深度学习抗体设计让学员通过不同方向不同方法更全面的了解蛋白质设计当下的全面性!六天培训流程循序渐进!知识点全覆盖!更是讲解十篇顶刊文献,让学员更好的知道当下蛋白质设计的核心热点以及优势
主讲老师在学术界和工业界都有丰富算法开发和应用经验,毕业于南开大学院士课题组,从事AI多肽设计、抗菌肽设计以及蛋白质设计的研究工作,相关工作成果已在New England、Plos one等国际知名期刊发
AI多肽设计课表
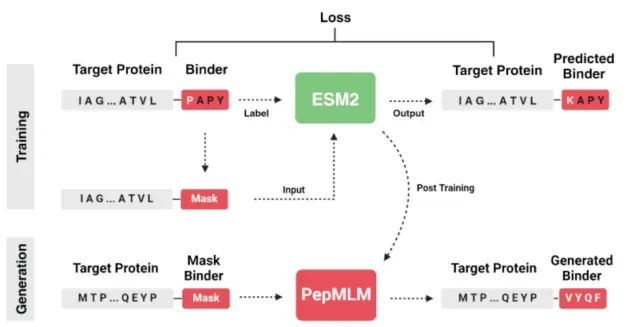
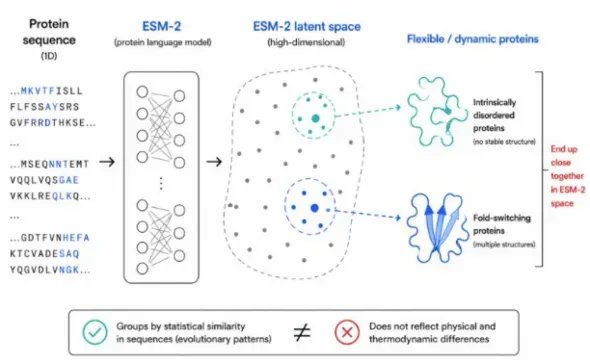
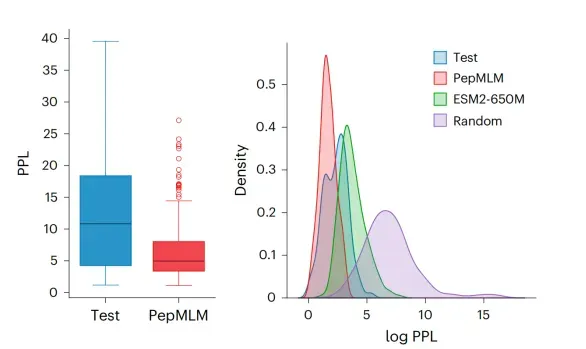
让学员更好的知道当下蛋白质设计的核心热点以及优势能独立完成蛋白结构可视化:用 PyMOL 加载复合物、识别结合界面、测量相互作用、渲染高清结构图。能使用 ESM2 完成序列评分,用 PepMLM 实现靶标定向短肽生成,并通过 Python 完成数据清洗、筛选与可视化。能用 AF2/Multimer 预测肽 - 蛋白复合物结构,解读 pLDDT/ipTM/PAE 指标,完成界面分析与质量评估。能用 LigandMPNN 基于固定骨架优化短肽序列,结合多指标完成候选肽筛选与成药优化方案设计。建立AI 短肽设计完整思维闭环:靶点选择→候选生成→性质筛选→结构评估→优化验证。具备独立解决实操问题的能力,能合理解读 AI 预测结果、规避模型局限,输出可实验验证的短肽候选。掌握跨工具联用能力,实现 ESM2、PepMLM、AF2、LigandMPNN、PyMOL 的流程化配合使用。
AI抗体设计课表
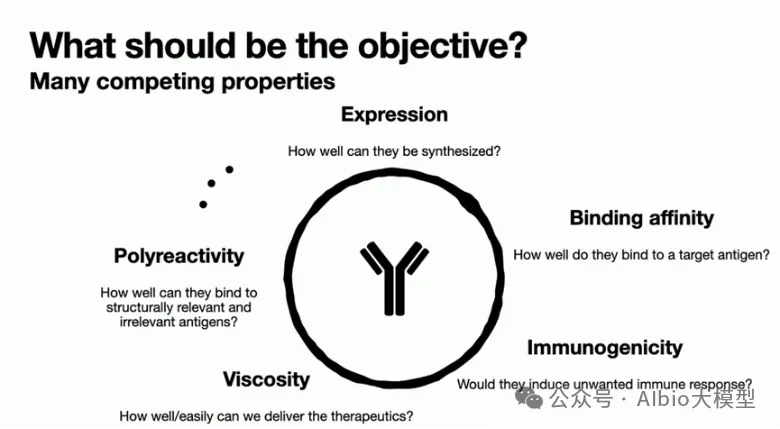
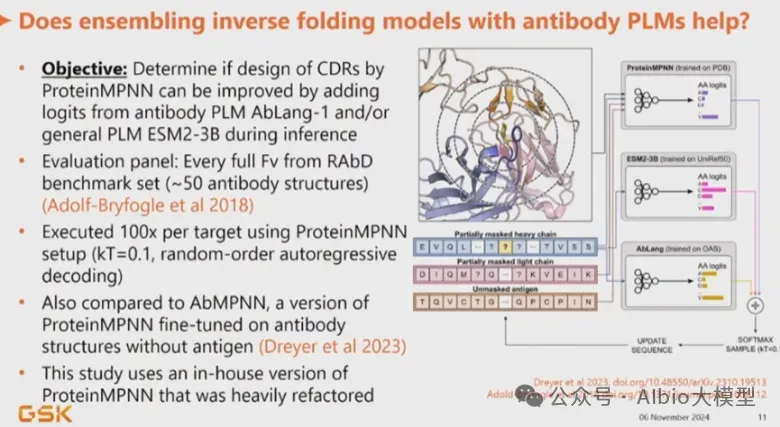
培训聚焦深度学习驱动的抗体设计为核心方向,以David Baker实验室核心设计方法、主流抗体大语言模型、AI抗体结构预测模型为教学核心,秉持理论夯实、实操落地、科研进阶、工程应用的培训原则。依托高性能服务器实操环境,循序渐进讲解行业主流软件、开源模型、代码实操、数据处理与模型调优,搭配十篇顶刊经典文献深度解析,全方位覆盖当下抗体设计领域前沿技术、研究热点与工业落地方案。助力零基础及进阶学员快速打通理论原理、代码实操、模型应用、科研创新全流程,熟练掌握AI抗体设计全套技术栈,可独立完成抗体结构预测、抗体亲和力优化、可开发性改造、抗体从头设计等科研实操任务,适配药物研发、生物工程、合成生物学等科研与工业应用场景。
主讲老师在学术界具有多年的研究经历和应用经验,来自于国内顶尖课题组,从事基因组编辑技术与人工智能交叉融合的研究工作,相关工作成果已在Nature Biotechnology、Nature Plants、Trends in Biotechnology等国际知名期刊发表
AI+基因编辑课表
第一天
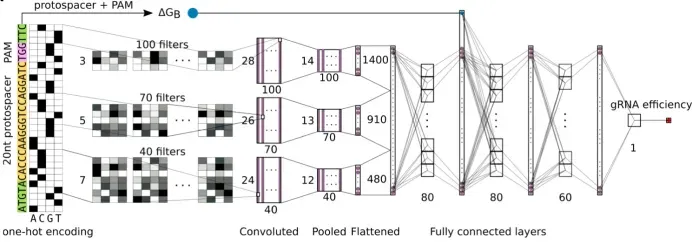
本次培训聚焦基因组编辑技术体系与人工智能辅助基因编辑设计前沿方向,系统讲解CRISPR基因编辑全套技术原理、编辑工具、脱靶检测、实验流程、主流设计分析软件;深入剖析深度学习在gRNA优化、编辑活性预测、编辑酶改造、新型编辑系统挖掘中的核心应用。培训秉持理论扎实、通俗易懂、实操落地、案例复刻、科研进阶的教学理念,依托高性能GPU服务器,手把手完成Linux环境配置、深度学习模型搭建、AI蛋白进化、从头设计、结构比对、新型CRISPR挖掘等高阶实操。结合当下主流AI生成模型、大语言模型、结构比对工具,复刻多篇顶刊经典研究案例,使学员能够完整掌握传统基因编辑+人工智能基因编辑全流程技术栈,具备独立开展基因编辑载体构建、gRNA智能优化、编辑酶定向进化、新型编辑元件挖掘、人工设计结合蛋白等科研能力,适配植物育种、基因治疗、生物医药、分子诊断等科研及工业研发场景。
主讲老师来自浙江大学,主要研发方向为组学算法开发与虚拟细胞建模,以第一作者(含共同)发表高水平期刊会议论文数篇,包括Nature Communications,ISBI等,承担各层次研发课题3项,领导共创开源社区搭建,github star数百,具有丰富的科技成果转化落地经验,讲课一致受到学员高度评价。
AI构建虚拟细胞课表
第一天| 细胞数据数字化与基础表征
• 技术栈回顾:从数据→状态→调控→动态→药物→疾病→孪生→临床• 前沿趋势:大模型、多模态、空间组学、虚拟敲除• 职业发展:计算生物学人才需求与能力路径配套资源
AI蛋白质设计设计授课时间
共计6天的课 通过腾讯会议直播 线上实操 提供全部录播
AI+多肽设计授课时间
2026.7.04-2026.7.05(09:00-11:30--13:30-17:00)
2026.7.7-2026.7.8(19:00-22:00)
2026.7.11-2026.7.12(09:00-11:30--13:30-17:00)
共计5天的课 通过腾讯会议直播 线上实操 提供全部录播
03
AI抗体设计授课时间
04
AI+基因编辑授课时间
05
AI构建虚拟细胞授课时间
培训费用及福利
课程报名费用:
公费价:每人每班¥6880元 (含报名费、培训费、资料费、提供课后全程回放资料)
自费价:每人每班¥6580元 (含报名费、培训费、资料费、提供课后全程回放资料)
重磅优惠:
报二送一(同时报名两个班免费赠送一个学习名额赠送班任选)
优惠1:
两班同报:10880元 (可学习三个直播课)
三班同报:14880元
四班同报:18880元
特惠一:24880元 (可免费学习一整年本单位举办的任意课程)
特惠二:28880元(可免费学习两整年本单位举办的任意课程)
优惠2:提前报名缴费可享受300元优惠(仅限十五名)
报名学习课程可赠送往期课程回放(报多少赠多少)
(可点击跳转详情链接):
回放一:本课程为视频课!机器学习生物医学培训!
回放二:本课程为视频课!单细胞空间转录组培训!
回放三:本课程为视频课!比较基因组学培训!
回放四:本课程为视频课!机器学习蛋白质组学培训
回放五:本课程为视频课!机器学习微生物组学培训
回放六:本课程为视频课!蛋白质晶体结构解析培训
回放七:本课程为视频课!CRISPR-Cas9基因编辑培训
回放八:本课程为视频课!机器学习代谢组学培训!
回放九:本课程为视频课!深度学习基因组学培训!
1、课程特色--全面的课程技术应用、原理流程、实例联系全贯穿
2、学习模式--理论知识与上机操作相结合,让零基础学员快速熟练掌握
3、课程服务答疑--主讲老师将为您实际工作中遇到的问题提供专业解答
授课方式:通过腾讯会议线上直播,理论+实操的授课模式,老师手把手带着操作,从零基础开始讲解,电子PPT和教程开课前一周提前发送给学员,所有培训使用软件都会发送给学员,有什么疑问采取开麦共享屏幕和微信群解疑,学员和老师交流、学员与学员交流,培训完毕后老师长期解疑,培训群不解散,往期培训学员对于培训质量和授课方式一致评价极高!
学员对于培训给予高度评价
腾讯会议实时直播解答|手把手带着操作
引用本次参会学员的一句话: