英伟达深圳闭门会:三个信号,一个比一个猛
- 2026-06-18 22:05:30
技术变革从来不是突然发生的,但它发生的时候,往往比所有人预期的都快。
人间温柔,皆因母爱。先祝全天下的母亲,节日快乐,被时光温柔以待。
一场不一样的技术分享会
5月8日,深圳湾万怡酒店,NVIDIA AI Open Day深圳站。
作为GBA OPC联盟代表,我受邀参加了这场活动。说实话,去之前我以为又是一场常规的技术路演,但三个小时听下来,感觉不太一样——英伟达传递的信号,比我想的要猛。

这篇文章不是流水账式的活动报道,而是我从技术细节中提炼出的行业信号。三位嘉宾,三种视角,却指向同一个方向——AI正在重新定义软件开发的基本范式。
第一个信号:英伟达在"抢人",而且很诚实

第一位嘉宾的分享,我到得晚,没赶上名字,但Key Learnings这三句话,我觉得是整场活动最接地气的部分。
第一句:Decouple your job from your tasks.
把你的工作从任务中解耦。这句话听起来有点绕,但我理解他的意思是:不要让你的身份和具体的任务绑定太深。在AI时代,单个任务的边界正在变得模糊,今天你是一个"写代码的",明天可能变成"定义问题的"。
第二句:AI is empowering engineers, but not replacing them.
AI在赋能工程师,不是替代他们。这句话在活动现场被英伟达用绿字高亮了"We are actively hiring excellent engineers"——英伟达正在积极招聘优秀工程师。
这句话很实在。如果连全球最懂AI的公司都在喊"我们还在招人",那些鼓吹"程序员要被替代"的声音,至少在可预见的未来,显得有些过于乐观了。
第三句:The honest part — the boundary is moving.
最诚实的部分:边界正在移动。
我觉得"边界正在移动"是整场活动最有分量的一句话。它不是危言耸听,也不是粉饰太平。它承认变化会发生,但同时也在说:现在还没定,我们还在塑造这个边界。
第二个信号:从"人写代码"到"Agent写代码"

第二位嘉宾是Luis Ceze,NVIDIA VP of AI Systems Software。他的演讲主题是:Programming NVIDIA GPUs at Speed-of-Light Performance for AI Agents (and Humans)。
这个标题本身就透露了关键信息:AI Agents和Humans并列。不是从属关系,是并列关系。这可不是随手的措辞。
光速文化与AI进化飞轮
Luis Ceze提到了一个"AI进化飞轮"的概念:智能体互相学习,加上工具链反馈,加上开源生态,这三者形成正循环,呈指数级加速。
他给了一个具体目标:SoL(Speed of Light,光速)= 硬件100%利用率。通过Python高级语言,获得90%以上的光速性能,不需要手写PTX汇编。翻译成大白话:用最简单的语言,榨干硬件的性能。
这句话对工程师意味着什么?意味着门槛在降低。以前要写出接近硬件极限性能的代码,需要深度掌握CUDA、PTX这些底层语言,门槛很高。现在,通过更高级的抽象,依然可以达到90%以上的性能。
现代CUDA技术栈的重构
Luis Ceze详细介绍了NVIDIA的技术栈分层:
第一层是Frameworks,包括PyTorch、Jax、TensorRT-LLM;第二层是Libraries,包括cuDNN、cuBLAS这些核心库;第三层是Tile-level languages,包括cuTile、CUTLASS、Triton;第四层是CUDA C++和Python;最底层是PTX和NVVM。
这里的关键变化是:统一语言cuda-lang。他们希望通过Python DSL整合所有编译器后端,服务两类用户——普通开发者和内核开发者。
Agent正在成为GPU的"第一类用户"
这是Luis Ceze演讲中最颠覆认知的部分。他明确指出,人类和AI智能体对技术栈的需求完全不同:
人类需要清晰报错、Nsight分析工具、优美的文档。智能体需要机器可读的Benchmarks(JSON格式)、结构化IR、编译器诊断API。
这两类需求差异巨大。面向人类的工具,讲究可读性和交互性;面向智能体的工具,讲究机器可解析性和高吞吐量。
他提到了一个里程碑式的进展:在Blackwell架构上,AI自主生成的内核性能已经超越了人工调优的FlashAttention-4和cuDNN。
这句话的分量很重。FlashAttention-4和cuDNN都是业界公认的最高性能内核库,是人类工程师多年优化的结晶。AI生成的内核能在Blackwell上超越它们——注意,这已经不是"接近",是"超越"。
还提到了一个验证工具ProofWright:双智能体验证流水线,自动证明74%生成内核的语义等价性。74%这个数字,意味着超过三分之二的AI生成内核能通过自动验证,平均每个内核验证时间只需3分钟。
Luis Ceze的结论是:编译器与智能体共进化,编译器不再是静态工具。编译器会根据智能体的反馈持续优化,智能体会成为编译器的"共同设计者"。
第三个信号:英伟达在开源上押了重注
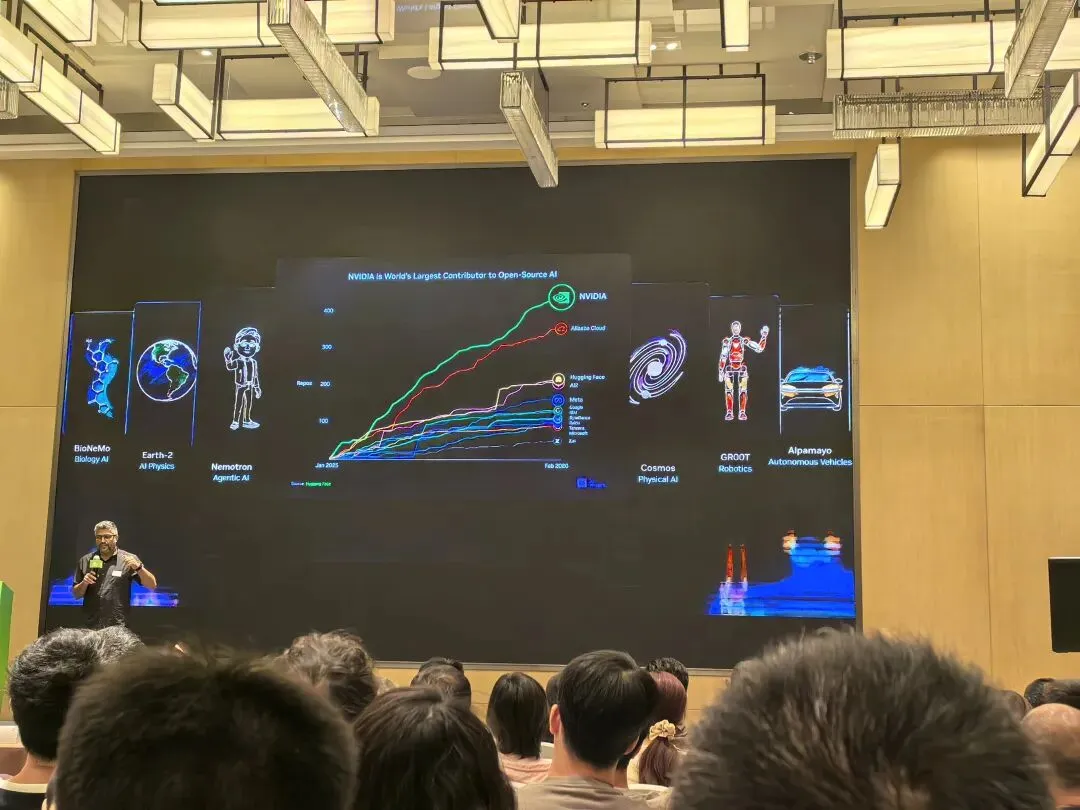
第三位嘉宾是Ankit Patel,NVIDIA VP of Developer Ecosystem。他的演讲主题是:Open Models from Open Training to Open Serving — NVIDIA's ongoing investment and support in the OSS AI stack。
如果说Luis Ceze讲的是"技术怎么进化",那Ankit Patel讲的就是"英伟达在赌什么"——而赌注之大,出乎我意料。
六大关键开源项目
Ankit Patel详细介绍了NVIDIA在开源领域的六大关键项目:
TensorRT-LLM:官方参考大模型推理引擎;Dynamo:解耦推理服务框架;CUTLASS:高性能计算模板库,核心前端已开源;FlashInfer:最先进推理内核库;cuTile编译器:从编程语言到TileIR层级都已开源;cuDNN前端已开源,底层也在逐步开放。
这份清单释放了一个明确信号:英伟达正在有计划地开放自己的核心技术栈。不是蜻蜓点水式的"开放几个工具"敷衍一下,而是系统性的——从上层框架到中间编译器到底层库的全面开放。
Agent First的战略
Ankit Patel重申了"Agent作为第一类用户"的战略。他指出,技术栈的接口正在被重新设计,要同时支持人类的高交互性需求和智能体的高吞吐需求。
具体到cuTile内核工厂,端到端编程智能体(cuTile Skill)能实现从自然语言描述到cuTile内核的自动生成。在Blackwell B300上,AI生成的内核比PyTorch原生快1.23倍至5倍以上。
他还提到了TileGym内核工厂项目:Qwen 3.5的内核覆盖率从0%提升到了67%。从零起步,覆盖三分之二的核心计算场景,这个速度很惊人。
LLM推理优化的最新进展
在LLM推理优化方面,Ankit Patel介绍了投机采样(Speculative Decoding)技术。原理很巧妙:用轻量级的"草稿模型"做预测,再由大模型验证。这样可以有效突破内存带宽限制,显著降低首字延迟(Time to First Token)。
TensorRT-LLM现在支持多种变体,包括Medusa和动态草稿模型。企业可以根据自己的场景选择合适的方案。
Ankit Patel的愿景总结是:智能体作为编译器的共同设计者,软件栈形成自我优化循环。
写在最后
这场活动的信息密度很大,我整理出了三条核心脉络:
第一,边界正在移动,但主导权还在人手里。 英伟达在积极招聘工程师,不是因为他们慢了,而是因为他们知道,最终定义这个边界的,还是人。AI是工具,但握着工具的人决定工具怎么用。
第二,从"人写代码"到"Agent写代码"的范式转变正在发生,但还处于早期。 AI生成的内核能超越FlashAttention-4,说明这个方向是可行的。但74%的验证率意味着还有26%的生成结果需要人类介入把关。效率大幅提升,但完全自动化还有距离。
第三,英伟达在开源上的投入,是一场豪赌。 把自己最核心的技术栈逐步开放出去,短期看似乎是在培养竞争对手。但长期看,生态的繁荣才是英伟达真正的护城河。更多的人在CUDA生态上开发,意味着对NVIDIA硬件的依赖度只会更高。
技术变革从来不是突然发生的,但它发生的时候,往往比所有人预期的都快。
你觉得这三个信号里,哪个最值得关注?或者你看到了我没注意到的方向?评论区聊聊,我看到都会回。
往期回顾:
每天4小时Vibe Coding,我终于明白了小白和高手之间差了什么


